Los rastreadores web son programas de descarga y procesamiento masivo de contenidos de Internet. También se les suele llamar “arañas”, “robots” o incluso simplemente “bots” En esencia, un rastreador hace lo mismo que cualquier navegador web ordinario: envía peticiones HTTP a los servidores y recupera el contenido de sus respuestas. Pero lo que ocurre después es otra historia: mientras que un navegador procesa y renderiza ese contenido para que los usuarios interactúen con él, un rastreador lo analiza y extrae los datos que cumplen ciertos criterios. Esto incluye recuperar enlaces a otras páginas y rastrearlas también. Recuperar la página, parsear la página, procesar los datos, encontrar enlaces a otras páginas, enjuagar, lavar, repetir: eso es un rastreador básico en pocas palabras.
¿Qué es el rastreador web?
Los rastreadores web son programas de descarga y procesamiento masivo de contenidos de Internet. También se les suele llamar “arañas”, “robots” o incluso sólo “bots” En esencia, un rastreador hace lo mismo que cualquier navegador web ordinario: envía peticiones HTTP a los servidores y recupera el contenido de sus respuestas. Pero lo que ocurre después es otra historia: mientras que un navegador procesa y renderiza ese contenido para que los usuarios interactúen con él, un rastreador lo analiza y extrae los datos que cumplen ciertos criterios. Esto incluye recuperar enlaces a otras páginas y rastrearlas también. Recuperar la página, parsear la página, procesar los datos, encontrar enlaces a otras páginas, enjuagar, lavar, repetir: eso es un rastreador básico en pocas palabras.
Sin embargo, los rastreadores del mundo real hacen mucho más que eso. Se utilizan en muchos lugares diferentes para muchos propósitos distintos. Por ejemplo, los rastreadores son los componentes principales de motores de búsqueda como Google, Yahoo, Bing y otros. Estos ejércitos de rastreadores buscan, recuperan, analizan e indexan constantemente el contenido de la web. Gracias a su interminable labor, puede contar con la posibilidad de encontrar contenidos que coincidan con sus intereses con sólo teclear su petición en un pequeño cuadro de búsqueda.
Otra tarea de los rastreadores es el archivo de sitios web. Los rastreadores avanzados pueden crear copias completas del contenido de un sitio web de forma periódica y guardarlas en un repositorio donde se pueden recuperar, ver y comparar entre sí, formando una línea de tiempo de los cambios en el transcurso de días, meses o incluso años. El contenido almacenado de este modo está firmado digitalmente, por lo que puede incluso utilizarse como prueba en los tribunales.
Otro uso popular de los rastreadores es la minería de datos, extrayendo información del contenido de la web y convirtiéndola en un formato comprensible para su uso posterior. Un buen ejemplo de ello es el bot de Google AdSense, que busca las páginas en las que aparecen anuncios de AdSense y comprueba si se infringen las políticas.
Los rastreadores web también se utilizan a menudo con fines de supervisión. Los rastreadores pueden comprobar automáticamente si los sitios web y las aplicaciones web funcionan correctamente, lo que ayuda a garantizar que el tiempo de inactividad sea mínimo y que cualquier error se solucione rápidamente.
Por último, pero no menos importante, los rastreadores web también se utilizan para el scraping. La mayoría de los portales corporativos no ofrecen ninguna forma fácil de exportar el contenido que proporcionan en un formato útil, y los que lo hacen suelen ofrecer interfaces engorrosas y API lentas. Sin embargo, estos obstáculos no disminuyen la demanda de esos datos, y los rastreadores web son perfectos para la tarea de extraerlos. Los rastreadores especializados, llamados “scrapers”, están diseñados para sortear las medidas contra el rastreo que implementan dichos portales emulando el comportamiento de navegación ordinario, haciéndoles creer que un humano está navegando por el sitio en lugar de un bot.
De estos ejemplos se desprende claramente que los rastreadores están siempre ocupados rastreando Internet, pero creemos que sigue siendo importante ilustrar la enorme magnitud del trabajo que pueden realizar con algunas cifras:
- Un rastreador llamado IRLbot funcionó en un superordenador durante dos meses seguidos. Recogió más de 6.400 millones de páginas durante ese periodo, trabajando a un ritmo medio de aproximadamente 1.000 páginas por segundo, y extrajo más de 30.000 millones de URL.
- Desde 1995, los rastreadores de Google y Yahoo han indexado más de 1 billón de páginas en conjunto.
Desafíos del rastreo web
Los rastreadores tienen una gran demanda y pueden ser una inversión lucrativa. Pero también hay que tener en cuenta una serie de advertencias sobre su funcionamiento y mantenimiento:
Desafíos técnicos de alto nivel
- Los rastreadores a escala industrial son sistemas distribuidos de alta carga con enormes demandas de almacenamiento y ancho de banda. Necesitará una flota de servidores de alta gama para hacer funcionar uno, junto con un equipo capacitado para implementarlo y mantenerlo. Cuanto más complejo sea su rastreador, más le costará en términos de infraestructura y soporte.
- El rastreo web es un campo competitivo, no sólo entre los rastreadores y las medidas contra el rastreo, sino también entre diferentes rastreadores en las mismas líneas de trabajo. Un rastreador ingenuo desperdiciará preciosos ciclos de reloj y ancho de banda que otros rastreadores más inteligentes dedicarán a procesar contenidos más relevantes. Sin una optimización adecuada, sería mejor no molestarse en ejecutar un rastreador.
- Hablando de rastreo ingenuo, un enfoque indiscriminado de la recopilación de contenidos puede tener graves repercusiones si su rastreador recoge material protegido por derechos de autor. Si no toma medidas para asegurarse de que esto no ocurra, podría enfrentarse a acciones legales si su rastreador viola los derechos de autor de alguien.
Teniendo en cuenta estos factores, está claro que un rastreador básico simplemente no va a ser suficiente para cualquier aplicación del mundo real. Desarrollar un rastreador eficaz requiere esfuerzo y consideración, y empieza por tener en cuenta los siguientes retos:
Retos de implementación
Escala de la tarea. Internet es un lugar enorme, y se hace más grande cada segundo. Para mantenerse al día con los datos más recientes (o incluso relativamente recientes), su rastreador debe ser rápido y eficaz. Con todas las cosas diferentes de las que debe ser capaz un rastreador eficaz, ¡esto puede ser complicado!
Procesamiento de contenidos. Lo ideal es que su rastreador procese todas las páginas que necesita y se salte todas las que no necesita. Parece un requisito bastante sencillo, ¿verdad? Por desgracia, es demasiado fácil acabar con un rastreador que se traga grandes cantidades de contenido irrelevante o que ignora resmas de datos valiosos. Una de las diferencias cruciales entre un rastreador inteligente y rápido y uno lento e ineficaz es la forma en que eligen los datos que van a recoger.
Cuidar los recursos que rastrea. Llevar todo el poderío de su rastreador a cada sitio web que encuentre es una buena manera de hacer un DDoS inadvertido a alguna víctima que no lo merezca – y posiblemente abrirse a una demanda. No sea una amenaza para Internet: debe asegurarse de que su rastreador es capaz de limitarse a sí mismo en función del rendimiento máximo del servidor al que intenta acceder.
Problemas de contenido dinámico. Ya hemos mencionado que los navegadores y los rastreadores hacen cosas muy diferentes con el contenido que recuperan de los servidores: los navegadores procesan y renderizan, mientras que los rastreadores analizan y extraen. Esto puede ser un obstáculo cuando un sitio web genera contenidos de forma dinámica, por ejemplo, utilizando JavaScript. Imagine una obra de teatro en la que los actores leen en voz alta las indicaciones del escenario en lugar de interpretarlas realmente: ese es el comportamiento típico de los rastreadores cuando se trata de guiones. Todavía es posible que un rastreador capte el contenido y los enlaces generados de esta manera, pero le advertimos de que hay que pagar un precio en términos de rendimiento.
Problemas con el contenido multimedia. Los sitios que hacen uso de Flash, Silverlight y HTML5 presentan su propio problema: sencillamente no hay forma de que un rastreador analice y extraiga los datos de un plugin o un objeto canvas. Lo que sí puede hacer es capturar el contenido de forma indirecta: por ejemplo, rastreando las peticiones realizadas desde un contenedor Flash. Cada tipo de multimedia debe abordarse por separado y, de nuevo, esto tendrá un impacto en el rendimiento general de su rastreador.
Problemas de rastreo de las redes sociales. Las redes sociales -Facebook, Twitter, Tumblr, Google+, Instagram, etc. – son una fuente inagotable de datos útiles y valiosos. Desgraciadamente, presentan todos y cada uno de los obstáculos para los rastreadores descritos anteriormente a la vez, ¡y algunos más! Podría ser tentador simplemente abrirse camino a través de los medios que las propias redes sociales proporcionan y utilizar sus API de cliente, pero éstas son limitadas tanto en términos de los tipos de datos a los que se puede acceder como de la eficiencia con la que se puede acceder a ellos – ciertamente no va a ser capaz de obtener una instantánea completa utilizándolas.
Conseguir un rastreador que merezca la pena la inversión ya parece una carrera de obstáculos, pero sólo estamos empezando. Hay una tarea más que hace que todo lo anterior parezca un juego de niños, y que merece un capítulo aparte: el rastreo de zonas protegidas.
Desafíos del rastreo de áreas protegidas
El rastreo de áreas protegidas es una de las tareas de rastreo web más difíciles que existen. Existen innumerables sistemas de autenticación diferentes, y su rastreador debe ser compatible con cada uno de ellos, o de lo contrario habrá enormes franjas de contenido a las que simplemente no podrá acceder. Muchos de nuestros clientes nos han pedido incluso que implementemos el rastreo de áreas protegidas como una característica específica, pero implementarlo es más fácil de decir que de hacer. He aquí un desglose de los retos que ofrece el rastreo de áreas protegidas:
Problemas de comportamiento de los rastreadores
La primera regla del rastreo en áreas protegidas es tan simple como vital: pise con cuidado. ¿Recuerda lo que hemos dicho antes sobre “no ser una amenaza para Internet”? Seguir todos los enlaces y realizar todas las acciones a las que tenga acceso es una receta segura para la destrucción de datos, usuarios enfadados y acciones legales dirigidas a usted y a su rastreador irresponsable. Tiene que asegurarse de que su rastreador
- No borrará nada que los usuarios puedan borrar (¡incluida la propia cuenta de usuario!)
- No intentará cambiar los datos de los usuarios (nombres de usuario, contraseñas, etc.)
- No realizará acciones de moderación de contenidos (por ejemplo, denunciar los contenidos de otros usuarios)
- No publicará contenidos
- No descartará las notificaciones de los usuarios
- Y así sucesivamente
La versión resumida es que debe encontrar la manera de asegurarse de que su rastreador se comporta de forma “sólo de lectura”. ¡Esto es más complicado de lo que parece! Imagínese que deja a un niño pequeño suelto sobre los preciosos datos de alguien, uno que no tiene la menor idea de lo que es o no es seguro tocar, de lo que puede soportar sus curiosos pinchazos y traqueteos sin romperse – y si está a punto de arruinar algo importante, lo más probable es que no pueda detenerlo a tiempo. Así es como se ve el gateo ingenuo de las áreas protegidas, y se necesita una programación sofisticada para asegurar que su gateador tenga un sentido de lo que es seguro tocar y lo que no.
Pero basta ya de hablar de posibles catástrofes del rastreador: para empezar, ¿cómo se introduce en las zonas protegidas? Vamos a ver algunos mecanismos de autorización habituales para que se haga una idea de la magnitud del problema:
Mecanismos de autenticación
Autenticación básica HTTP (BA). Es la forma más sencilla de imponer controles de acceso a los recursos web: sin cookies, sin identificadores de sesión, sin páginas de inicio de sesión, sólo cabeceras HTTP estándar. Casi todas las bibliotecas de red que encontrará por ahí la soportan out-of-the-box, así que es trivial soportarla en su rastreador, pero el precio de esta simplicidad es la falta de seguridad: BA no hace nada para proteger las credenciales transmitidas, aparte de codificarlas en Base64, lo que está a un paso de simplemente transmitirlas en texto plano. Por esta razón, BA -si se utiliza- debería usarse sobre HTTPS para garantizar alguna medida de seguridad.
Autenticación basada en certificados. Aunque la palabra “certificado” puede traer a la mente algo que colgaría en su pared o que daría como regalo en lugar de dinero en efectivo, aquí se refiere a una implementación de autenticación de clave pública. Un certificado es un documento digital que demuestra la propiedad de una clave pública: si el certificado tiene una firma válida de una autoridad de confianza, el navegador sabe que es seguro utilizar esa clave pública para una comunicación segura. Al igual que la autenticación básica, la autenticación basada en certificados es lo suficientemente común en las bibliotecas de red como para que no tenga problemas en soportarla en su rastreador, pero sí deberá obtener certificados válidos para cada área protegida que desee rastrear.
OAuth. OAuth es un estándar de autorización abierto que permite a los usuarios conceder a los sitios y aplicaciones un acceso seguro a sus datos sin tener que compartir su información de acceso. Si alguna vez ha utilizado su inicio de sesión de Microsoft, Google, Twitter o Facebook para entrar en un sitio web de terceros sin contraseña, se ha encontrado con OAuth en la naturaleza. Implementar el soporte de OAuth desde cero puede ser complicado, por lo que recomendamos aprovechar las bibliotecas existentes, como Scribe para Java.
OpenID. OpenID es un estándar de autenticación abierto que permite a los usuarios iniciar sesión en sitios web a través de un servicio de terceros. A diferencia de OAuth, que sólo se ocupa de la autorización (es decir, de conceder acceso a los datos entre sitios), OpenID proporciona un medio por el que los usuarios pueden autenticarse en varios sitios utilizando un único conjunto de credenciales. OpenID está ampliamente soportado por las bibliotecas existentes, lo que facilita su implementación.
Y ahora llegamos al tipo de autenticación más común en la web: la autenticación basada en formularios. Esto no necesita prácticamente ninguna introducción: al usuario se le presenta un conjunto de campos para introducir sus credenciales (normalmente un nombre de usuario y una contraseña), que luego son verificados por el servidor. Veamos paso a paso un proceso típico de autenticación basado en formularios:
- Un usuario no autorizado intenta acceder a una página segura
- El servidor responde con una página que contiene un formulario de autenticación
- El usuario introduce y envía sus credenciales mediante el formulario
- El servidor verifica las credenciales enviadas
- Si las credenciales son válidas, el usuario recibe un token/cookie/etc. de autenticación y es redirigido a la página segura
Y ahora echemos un vistazo a un típico formulario de autenticación:
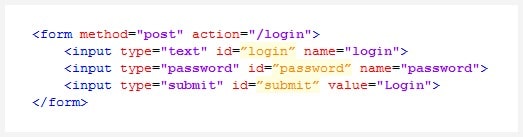
No es exactamente intimidante, ¿verdad? A primera vista, parece que sería trivial integrar la autenticación a través de este o cualquier otro formulario en su rastreador. Sería tan sencillo como
- Recuperar y analizar la página de autenticación
- Encontrar el formulario de autenticación y extraer el punto final y los parámetros
- Generar una solicitud POST con los parámetros extraídos del formulario y nuestras credenciales
- Ejecutar la solicitud y recibir el token/cookie/etc. de autenticación del servidor
- Arrastrarse
¡Si realmente fuera tan sencillo! En la práctica, se encontrará con escenarios como estos:
- El formulario de autenticación está dentro de un iframe y sólo funciona en la página de inicio de sesión
- El formulario de autenticación es generado por JavaScript
- El sitio utiliza un servidor de autenticación de terceros
- El punto final de autenticación y/o los parámetros se crean dinámicamente
- La autoridad del dominio del servidor de destino no coincide con la autoridad del dominio de autenticación
- La solicitud requiere una señalización digital dinámica
Su rastreador podría acabar teniendo que lidiar con cualquier combinación de estas complicaciones, como un formulario de autenticación generado por JavaScript desde un servidor de terceros con parámetros generados dinámicamente que requiere una firma digital. Por cierto, esto no es sólo el peor escenario hipotético: ¡es como solían funcionar los portales corporativos internos de McDonald’s!
Otra complicación potencial de la autenticación son las “tormentas de redireccionamiento”: ser rebotado entre múltiples servidores de autenticación, cada uno de los cuales establece sus propias cookies de autenticación. De nuevo, para un navegador, no es ningún problema, pero para un rastreador, hay que asegurarse de que cada página se evalúa correctamente para obtener todas las cookies y cabeceras necesarias para la autenticación. Por citar otro ejemplo de la vida real, ¡los portales corporativos de RJR Tobacco solían manejar la autenticación de esta manera!
Estos son sólo algunos de los retos a los que se enfrentará cuando rastree áreas protegidas. Codificar soluciones para cada caso individual simplemente no es una opción: hay demasiados escenarios diferentes que abordar. Sin embargo, lo que puede hacer es implementar una solución de “talla única” que pueda ajustarse para manejar cualquier situación que un sitio web pueda arrojar a su rastreador. Hablaremos de ello en el próximo capítulo.
Enfoques de implementación
Como se mencionó en el capítulo anterior, la mejor manera de manejar la autenticación en un rastreador es un enfoque de “navaja suiza”: en lugar de una miríada de herramientas para manejar cada escenario diferente, usted tiene una sola herramienta que puede manejar cada escenario. Parece una tarea difícil, ¿verdad? Puede serlo – pero es un territorio bien transitado, y hay dos caminos probados a través de él:
1. La personalización del mecanismo de autenticación a la carta (es decir, el scripting).
Para este enfoque, no hace falta decir que tendrá que añadir algún tipo de soporte de scripts a su rastreador. Una vez hecho esto, cree un script por defecto: un conjunto de instrucciones para manejar los formularios básicos de inicio de sesión con nombre de usuario y contraseña que utilizan la mayoría de los sitios web. Y siempre que su rastreador se encuentre con algo que su script por defecto no pueda manejar (hashtags adicionales, parámetros dinámicos, tormentas de redireccionamiento, etc.), todo lo que tiene que hacer es escribir un script de autenticación personalizado que se encargue de ello. Muy sencillo
Sólo hay dos problemas con este enfoque:
- No puede saber si su rastreador tiene problemas para entrar en el sistema a menos que alguien informe del problema
- Tiene que comprobar constantemente los sitios web en busca de cambios para mantener sus scripts actualizados
He aquí otro escenario de la vida real para ilustrar la cuestión. Hace algún tiempo, Redwerk implementó el rastreo de Facebook y Twitter. Sin embargo, en lugar de limitarse a recopilar información a través de sus API, nuestro rastreador se configuró para tomar instantáneas completas y funcionales por las que se podía navegar como si se estuviera en el sitio original. No es la forma más eficiente de hacer las cosas, y definitivamente no es la forma más fácil, pero conseguimos que funcionara utilizando scripts de autenticación personalizados – durante todo dos meses. Facebook y Twitter cambiaron sus sistemas de autenticación, y tuvimos que reescribir nuestros scripts de autenticación para que coincidieran. Desde entonces, ha sido un juego constante del gato y el ratón: de vez en cuando modifican su autenticación, y tenemos que revisar nuestros scripts para que funcionen con la nueva configuración. Por si sirve de algo, los scripts eran la mejor y probablemente la única forma de conseguir lo que logramos, ¡pero tiene su coste en términos de mantenimiento!
2. Servicios basados en el motor del navegador
Un enfoque alternativo es crear un servicio de autenticación construido con un motor de navegador o un conjunto de herramientas web como PhantomJS, CasperJS o Node.js. Teniendo en cuenta todos los problemas que surgen debido a las diferencias entre la forma en que los rastreadores y los navegadores procesan los sitios web, sólo tiene sentido ocuparse de uno de ellos tendiendo un puente entre los dos: salvo que se adopten medidas severas contra el rastreo, un servicio de autenticación basado en el motor del navegador garantizará que los sitios web funcionen exactamente igual para su rastreador que para los usuarios. Incluso los contenidos Flash y HTML5 funcionarán perfectamente para su rastreador
El proceso es sencillo: su rastreador sondea su servicio de autenticación antes de intentar rastrear un área protegida de un sitio web, y su servicio se encarga de cualquier proceso de inicio de sesión que sea necesario.
También puede incluir un mecanismo de reautenticación que permita a su rastreador renovar automáticamente su autenticación si ésta caduca por algún motivo. La funcionalidad que debe proporcionar su servicio incluye:
- Servir las solicitudes del rastreador para realizar la autenticación (normalmente se hace mediante una API REST)
- Realizar dicha autenticación utilizando los parámetros recibidos del crawler (URL de acceso, credenciales, tiempos de espera, etc.)
- Recoger y devolver los resultados de autenticación pertinentes (cookies, cabeceras, tokens, etc.)
- Garantizar que los datos de autenticación sean únicos y no se compartan entre tareas (no querrá que alguien acabe rastreando su perfil, ¿verdad?)
Con la autenticación basada en el motor del navegador, no necesita una solución personalizada para cada situación inusual (aunque todavía tendrá que implementar formas de manejar la miríada de casos límite y de esquina que existen). Otra ventaja es que puede configurar un sistema de notificaciones que le informará cuando -y por qué- su rastreador no puede entrar en un sitio.
Y ahora que dispone de un servicio basado en el motor de búsqueda, ¿por qué limitarse a la autenticación? Su servicio puede hacer otras cosas que pueden facilitarle la vida: por ejemplo, rastrear las solicitudes del servidor y extraer recursos, haciendo trivial la obtención de contenidos generados dinámicamente. Incluso puede implementar toda la funcionalidad de su rastreador de esta manera, pero no es una tarea sencilla, y puede que no merezca la pena dependiendo del propósito de su rastreador.
Ambos enfoques tienen sus ventajas en diferentes circunstancias. No se deje encerrar en uno u otro: la fidelidad a una pila tecnológica concreta no le ayudará a realizar su trabajo.
Resumen
Somos muy conscientes de que ésta no es la única guía sobre rastreadores web: es usted libre de discrepar de cualquier cosa que hayamos dicho sobre el tema. Dicho esto, esta guía se basa en nuestra propia experiencia trabajando con rastreadores, y nuestros consejos se basan en soluciones a problemas que hemos encontrado. Esperamos que al menos le ayude a evitar algunos de los escollos con los que suelen encontrarse los recién llegados al rastreo web. Los rastreadores son sistemas complicados, pero si los maneja adecuadamente, puede conseguir resultados sorprendentes.
Acerca de Redwerk
La empresa Redwerk está especializada en la prestación de servicios de desarrollo de software de calidad para diversos sectores. Uno de nuestros puntos fuertes es proporcionar a las empresas soluciones de software de minería de datos y rastreo web, destinadas a recopilar la información para tomar decisiones estratégicas y mejorar los procesos empresariales. El equipo de Redwerk está siempre dispuesto a desarrollar nuevos productos y a actualizar los existentes para nuestros clientes.
Proyectos de rastreo web automatizado que hemos realizado
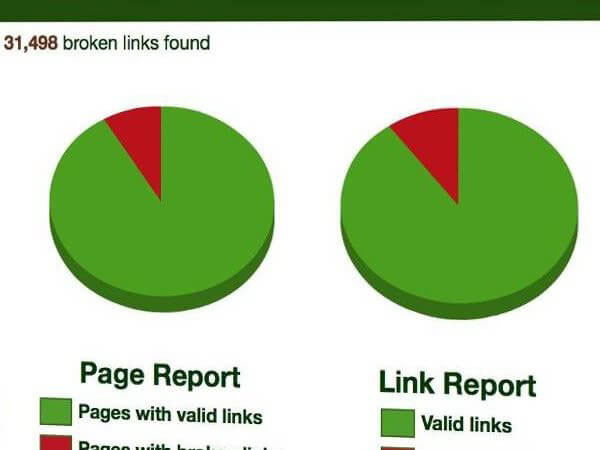
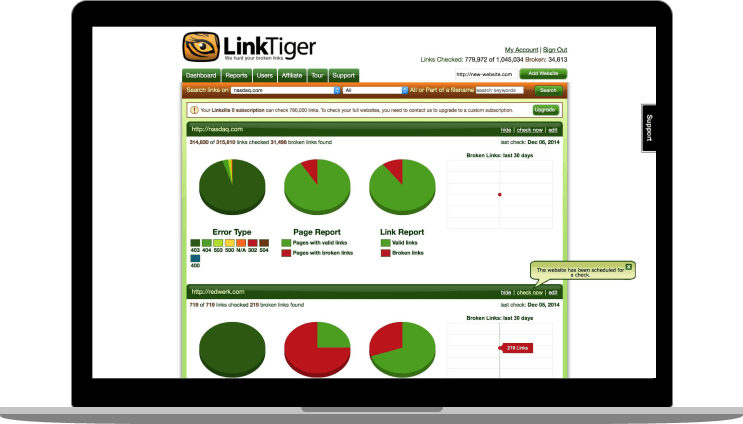
Escuche a nuestro cliente
“Redwerk es un proveedor de servicios informáticos especializado en el desarrollo de aplicaciones complejas, el control de calidad y el soporte. Su equipo está altamente cualificado, es puntual y suele ajustarse al presupuesto. Tienen un modelo de despliegue rentable y atienden las necesidades técnicas y empresariales de LinkTiger. He recomendado sus servicios a muchos colegas de negocios y me lo han agradecido” — Steve Moskowski, propietario de Linktiger.com
Vea cómo hemos desarrollado un sistema de rastreo de alto rendimiento desde cero