
El aprendizaje automático se aplica a una amplia gama de tareas empresariales: desde la detección de fraudes hasta la selección del público objetivo y las recomendaciones de productos, pasando por el control de la producción en tiempo real, el análisis de la tonalidad de los textos y los diagnósticos médicos. Puede hacerse cargo de las tareas que no pueden realizarse manualmente debido a la enorme cantidad de datos que hay que procesar. En el caso de un gran conjunto de datos, el aprendizaje automático revela a veces dependencias no evidentes que no pueden detectarse mediante un examen manual riguroso. En este caso, la combinación del conjunto de esas relaciones “débiles” da lugar a mecanismos de previsión que funcionan perfectamente.
El proceso de aprendizaje a partir de los datos y la posterior aplicación de los conocimientos para justificar decisiones futuras es una herramienta extremadamente poderosa. El aprendizaje automático se convierte rápidamente en el motor de una economía moderna impulsada por los datos.
En los últimos años, el aprendizaje automático (“ML”) se ha convertido en un gran negocio: las empresas lo utilizan para ganar dinero. La investigación aplicada se está desarrollando rápidamente tanto en el ámbito industrial como en el académico, y los desarrolladores curiosos de todo el mundo buscan una oportunidad para aumentar su nivel de experiencia en este campo. Sin embargo, la demanda emergente supera con creces la velocidad de aparición de buenas técnicas y herramientas.
En este post, nos gustaría describir cómo puede utilizar Microsoft Azure Machine Learning Studio para construir modelos de aprendizaje automático, así como los problemas que puede encontrar al utilizar Azure ML y cómo sortearlos.
Herramientas y fundamentos
Machine Learning Studio le permite construir rápidamente modelos, entrenarlos y elegir los más adecuados para su tarea. La gran ventaja de esta plataforma es la rapidez con la que se domina, lo que es positivo para los principiantes en ML. Pero para los desarrolladores experimentados, la plataforma ofrece muchas oportunidades, desde la computación en la nube (que permite procesar grandes cantidades de datos) hasta la facilidad de desplegar el modelo entrenado como un servicio web.
Puede explorar fácilmente la plataforma o incluso el ML en general utilizando una cuenta gratuita de Microsoft, esto impone algunas limitaciones, pero le permite familiarizarse con el sistema. Además, una cuenta gratuita es adecuada para crear modelos para pequeñas cantidades de datos.
Vamos a familiarizarnos con la plataforma en sí. Empiece por crear una cuenta en Azure Machine Learning Studio y consulte el menú:

- Proyectos – representan grupos de experimentos
- Experimentos – similares a los cuadernos ipython
- Servicios web
- Cuadernos – cuadernos ipython
- Datos guardados
- Modelos
- Configuración
Preste atención a la pestaña de ajustes:
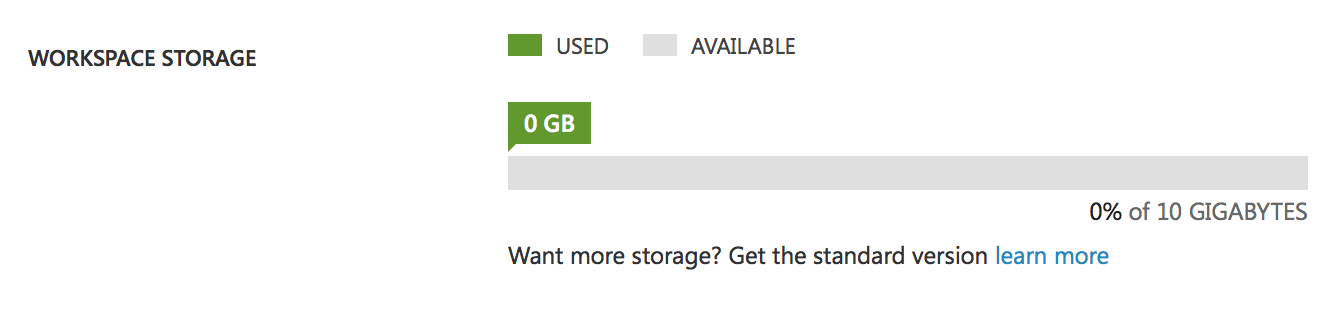
Este es nuestro espacio libre para datos, modelos y experimentos. 10 GB de almacenamiento es una de las limitaciones de la cuenta gratuita. Puede parecer que es suficiente, pero recuerde que Studio almacena todos los datos intermedios de los experimentos, es decir, si tiene un experimento con un volumen de datos de 1Gb, después de varios cambios o del lanzamiento del experimento su disco estará lleno y tendrá que borrar los datos intermedios. En una cuenta de pago esta restricción no existe, tendrá un disco casi infinito. Además, hay una diferencia más entre las cuentas: La cuenta gratuita sólo puede ejecutar un experimento a la vez, es decir, sólo tendrá un hilo, mientras que la cuenta Premium ofrece la posibilidad de ejecutar muchos experimentos simultáneamente o de crear procesos paralelos dentro de un experimento.
Creación de su primer experimento
Vamos a crear un experimento y a familiarizarnos con el proceso de construcción de un modelo.
Seleccione – añada el experimento y busque un ejemplo de Clasificación de textos.
Studio creará un experimento y descargará automáticamente los datos.
He aquí nuestro primer experimento:
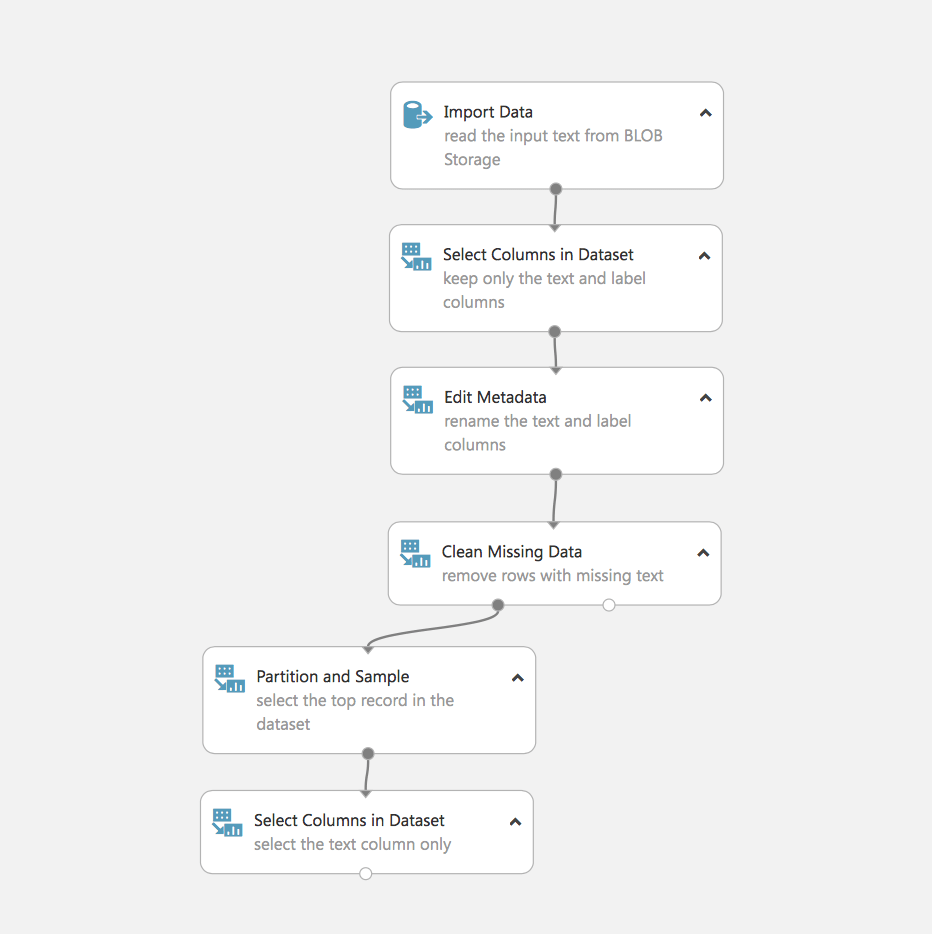
Veamos qué ocurre aquí. De hecho, vemos la primera tarea de la que se ocupa el ML, el procesamiento y la preparación de los datos.
- Cargar los datos (en nuestro caso están almacenados en Azure Blob)
- Seleccionar los campos necesarios
- Editar los metadatos
- Eliminación de los datos con los campos que faltan
- Dividir los datos
Ejecuta el experimento y examina los datos recogidos:
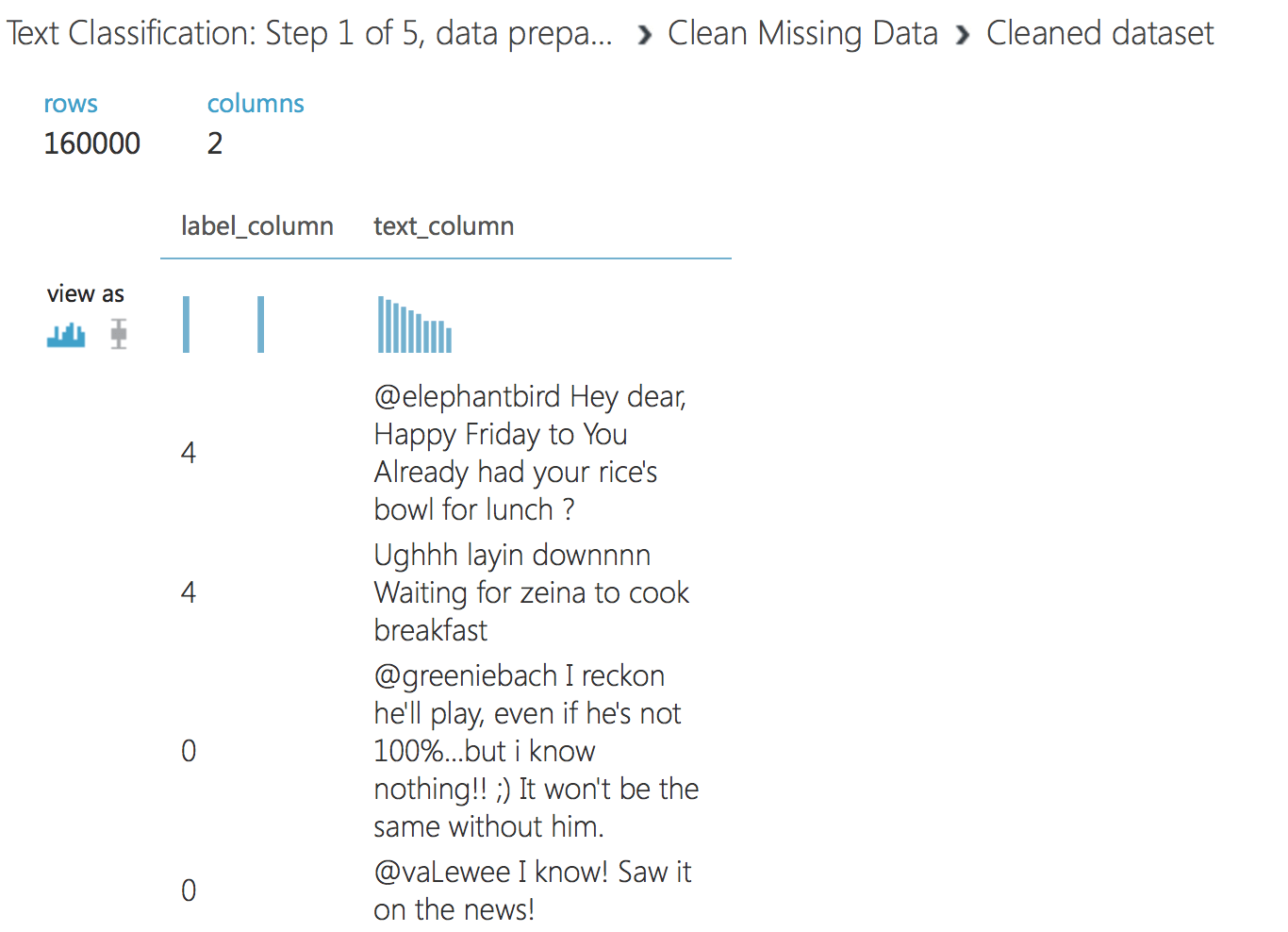
Hemos preparado los datos y estamos listos para pasar al siguiente paso. Cargue el siguiente experimento: Clasificación de textos: Paso 2 de 5, preprocesamiento del texto
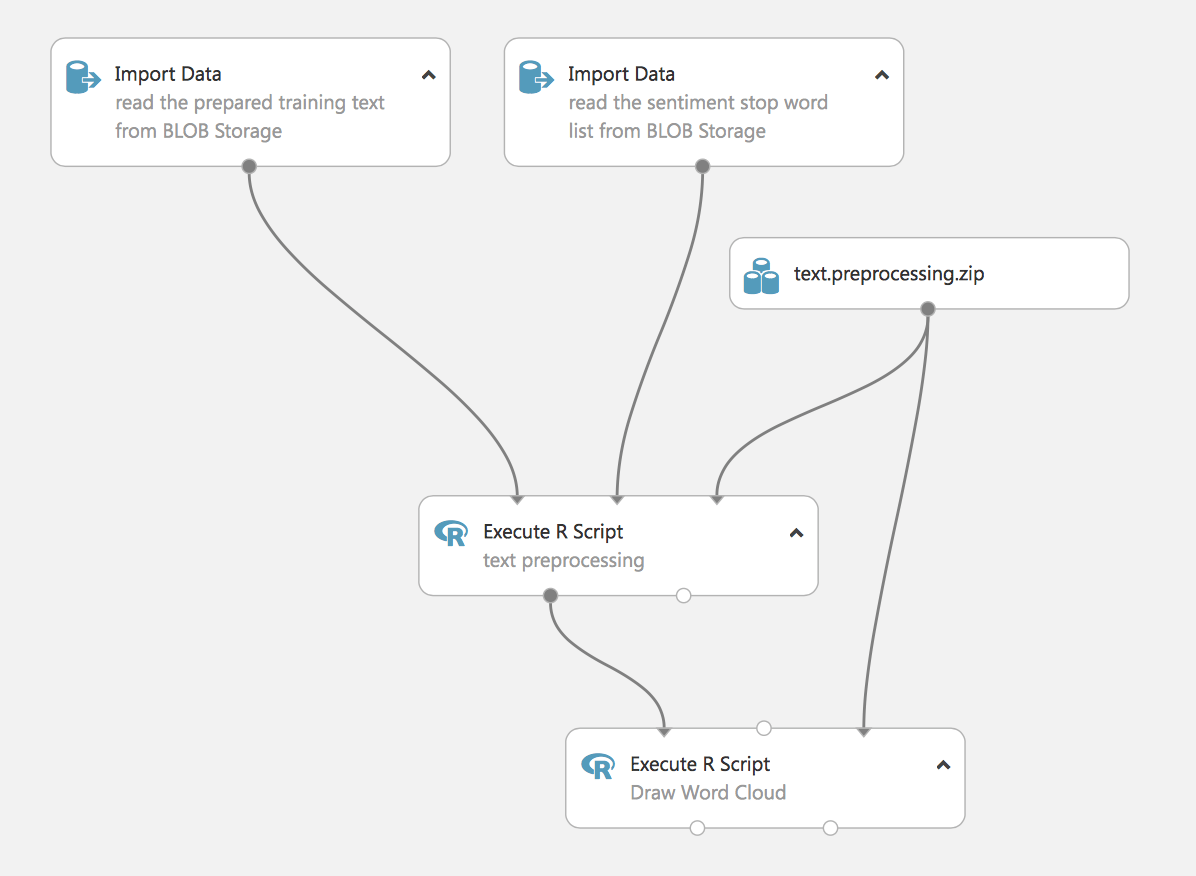
En esta etapa, cargamos los datos y los procesamos. En este experimento se utilizan scripts en R para eliminar las palabras vacías (también las cargamos desde blob).
El último paso consiste en visualizar la nube de palabras. Este es un experimento con valor práctico, demuestra la capacidad de Studio para utilizar scripts en R para tareas de ML, y también podemos incorporar scripts en Python al proceso. Más adelante, en el artículo, mostraremos un ejemplo de procesamiento de texto utilizando métodos estándar de Studio.
Vamos a ejecutar el experimento y a estudiar los resultados.
En la salida del primer script de R, vemos el texto redactado.

El segundo script genera una nube de palabras. Esto es a veces necesario para la visibilidad de los datos.

Sigamos adelante, cree el siguiente experimento, utiliza los datos del primer script del experimento anterior.
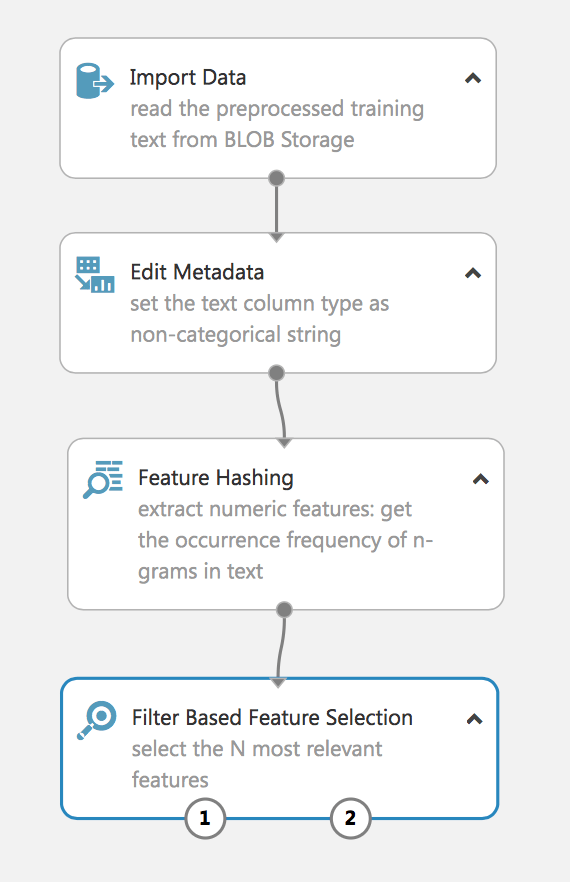
El experimento extrae los N-gramas de los datos de texto utilizando el método de Frecuencia de Términos y luego selecciona los más relevantes. Se suele utilizar un proceso similar para procesar el lenguaje natural.
Comprobemos los datos recibidos:

Como puede ver, hemos extraído con éxito la característica hashing de los datos de texto y hemos filtrado la más relevante. Si no se utiliza un filtro, entonces en una muestra de 160.000 obtendremos un vector en decenas de miles de características, y esto complicará la tarea de aprendizaje del modelo y puede llevar a un reentrenamiento.
El siguiente experimento demuestra otro enfoque para procesar NL-TF-IDF (Term Frequency Inverse Document Frequency).
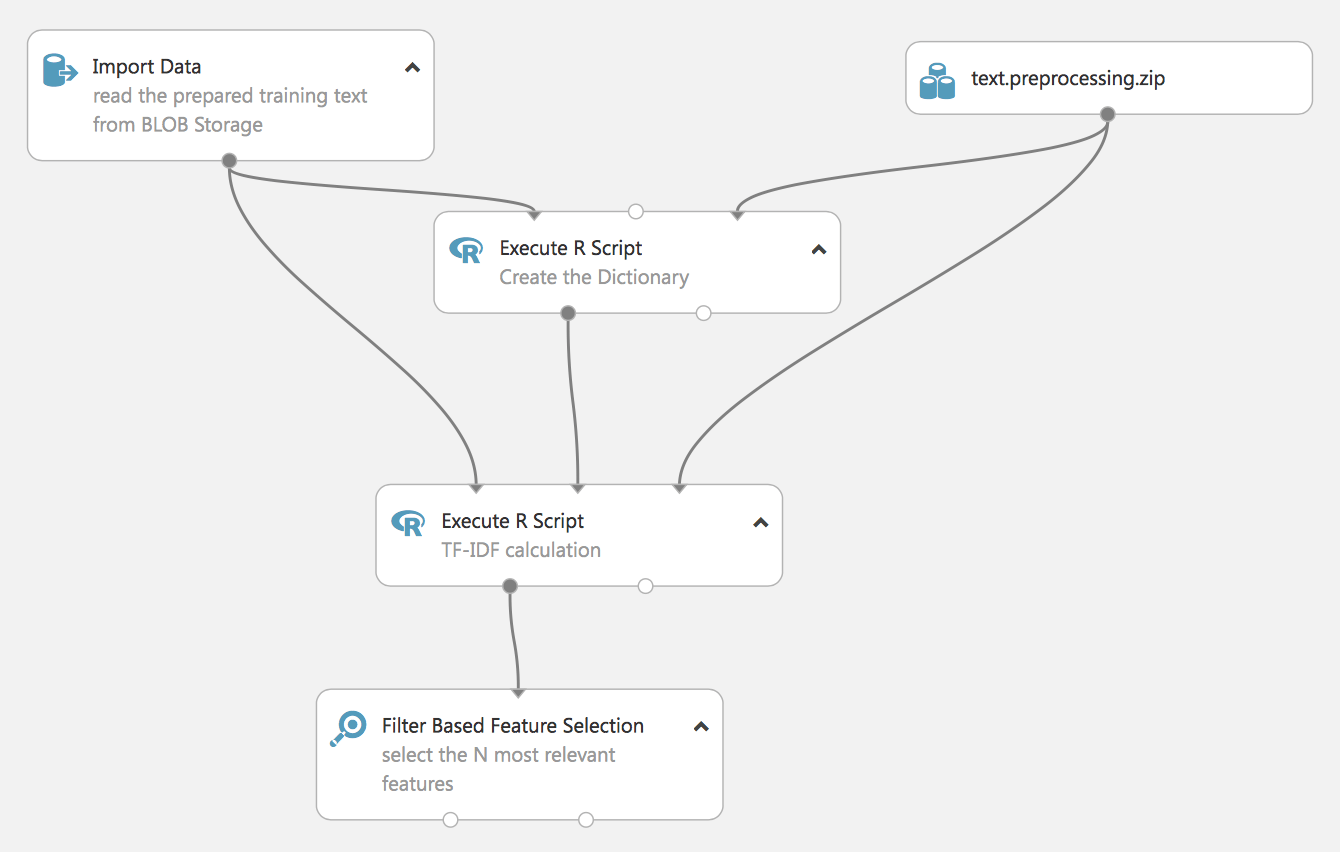
También está construido en lenguaje R, más adelante mostraremos cómo se puede hacer con las herramientas estándar de Studio.
El resultado del experimento será también el vector de características más relevante, pero construido sobre un diccionario previamente creado (que también se basa en nuestros datos), no se muestra en el experimento – pero no olvide guardar el diccionario, ya que será necesario para preparar los datos reales después.
Construyamos un modelo de aprendizaje de flujo.
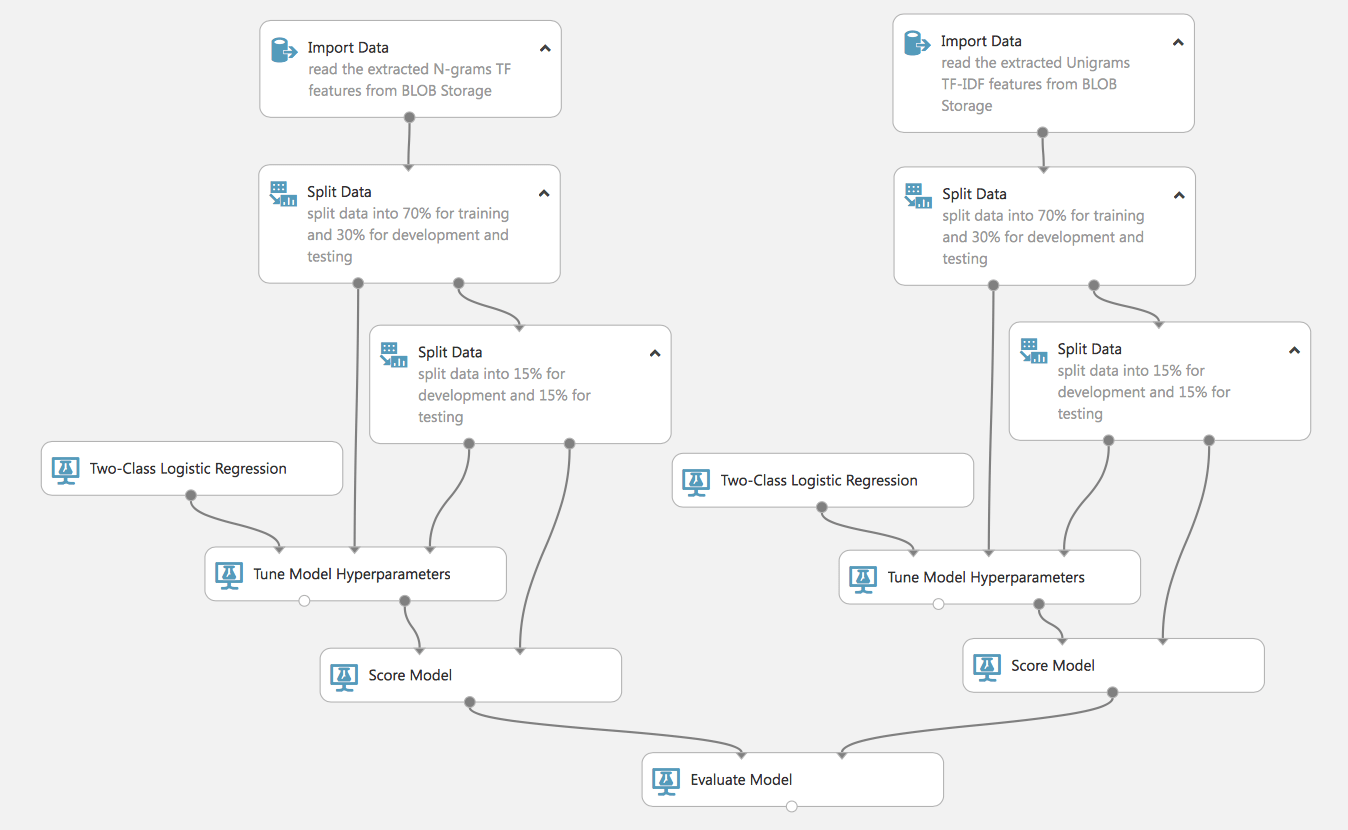
Como ve, podemos construir procesos complejos y paralelos (recuerde que en la cuenta gratuita todo esto se hará de forma secuencial, en la cuenta de pago, de forma simultánea, lo que reduce el tiempo de aprendizaje de los modelos). Asimismo, un flujo de este tipo nos permitirá entrenar 2 modelos y comparar su eficacia, es muy conveniente para elegir los modelos o métodos de preparación de datos más adecuados.
Veamos con más detalle este proceso. Al principio, tiene 2 conjuntos de datos preparados con varios métodos de TF, TF-IDF. Ambos conjuntos los dividimos en datos de entrenamiento y de prueba (que no participan en el entrenamiento del modelo y que se utilizarán para evaluar su calidad). Observe que compartimos el conjunto de datos de prueba por segunda vez, esto es necesario para el siguiente paso.
Declaramos un modelo (en este ejemplo utilizaremos la Regresión Logística), pero para una mayor eficiencia, incluiremos el análogo más cercano de GridSearchCV en el proceso de Sintonización de los Hiperparámetros del Modelo (para las librerías de sklearn que están familiarizadas con python). Es decir, no fijamos rígidamente los parámetros del modelo, sino que establecemos los parámetros de rango y los pasamos al bloque Tune Model, que seleccionará los más eficaces durante el entrenamiento del modelo. Para este bloque necesitamos un segundo conjunto de datos de prueba.
Vamos a ejecutar este flujo y a examinar los resultados.
Resultados de Tune Model:
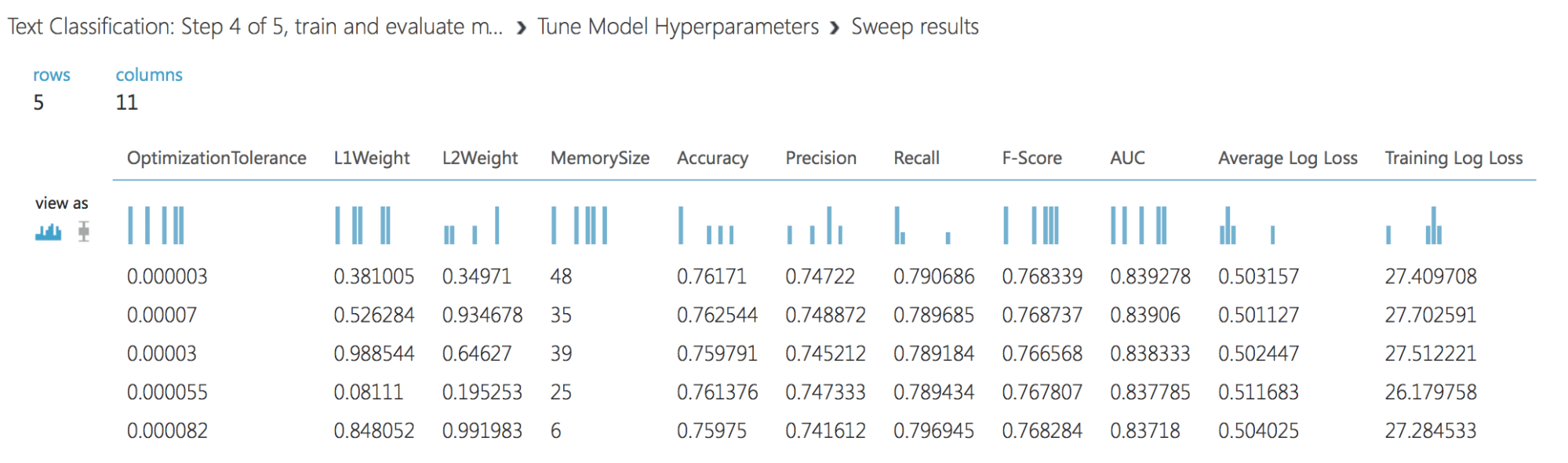
Y los parámetros del mejor modelo (va más allá para la evaluación):
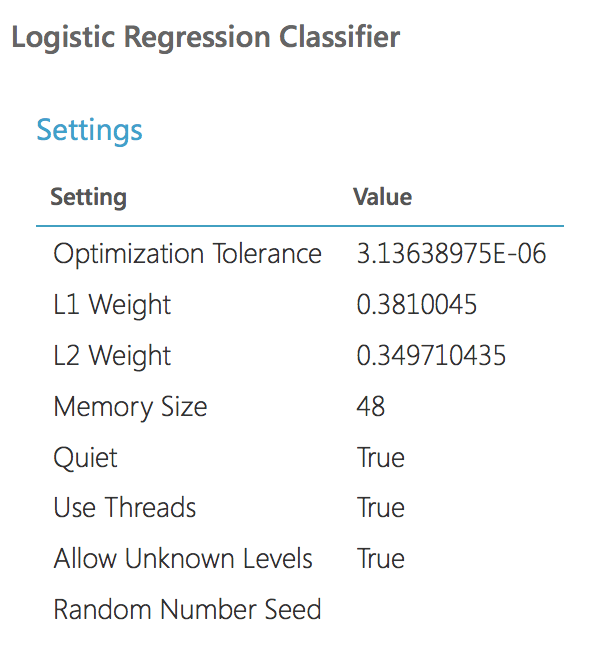
Como vemos los parámetros de los modelos son idénticos. Comparemos la calidad. Este es el gráfico ROC para dos modelos:
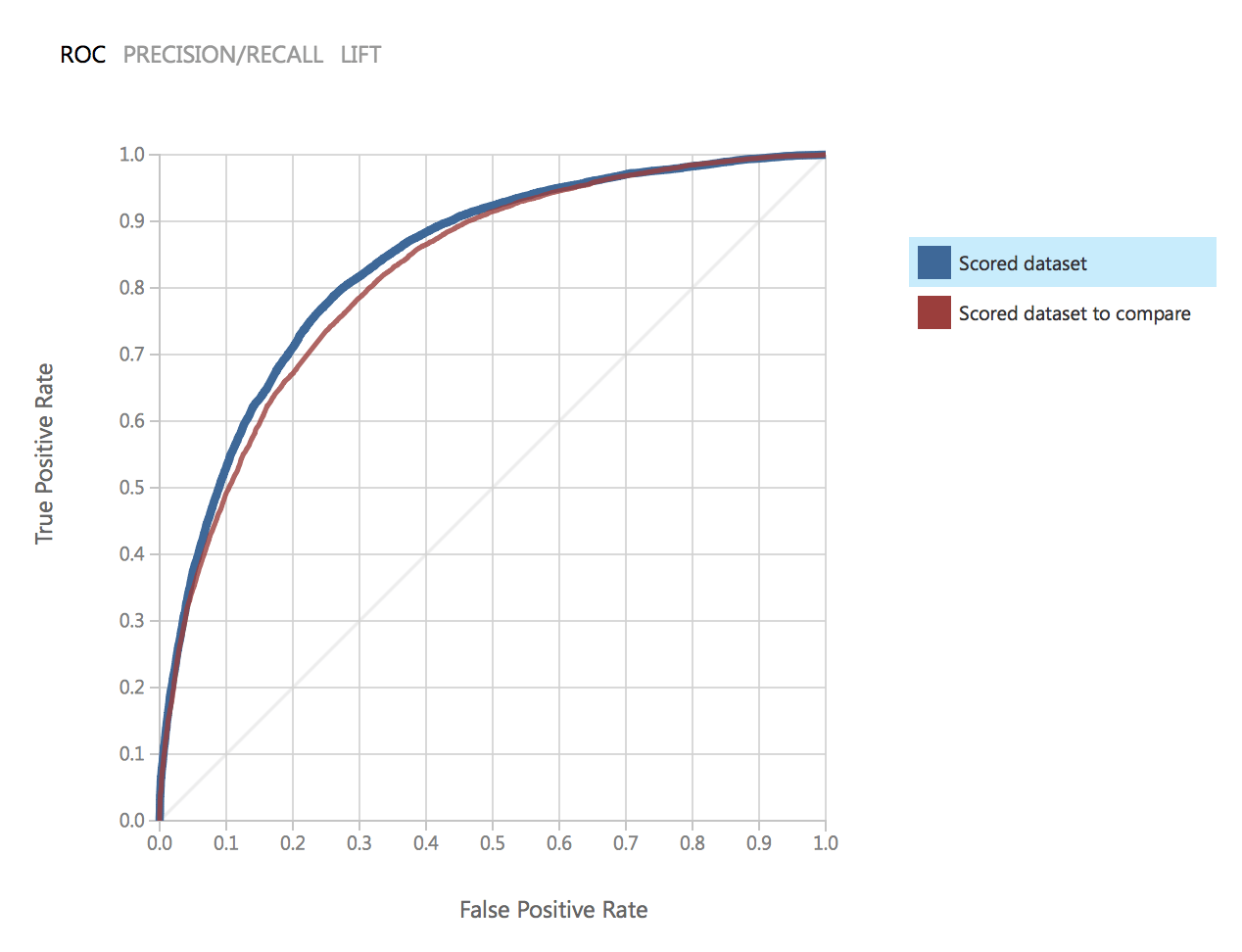
Como puede observarse, los resultados de ambos modelos están muy próximos y satisfacen nuestra precisión.
Sigamos adelante, y construyamos un experimento que permita utilizar el modelo para datos reales (por ejemplo, los que llegan a través del Servicio Web).
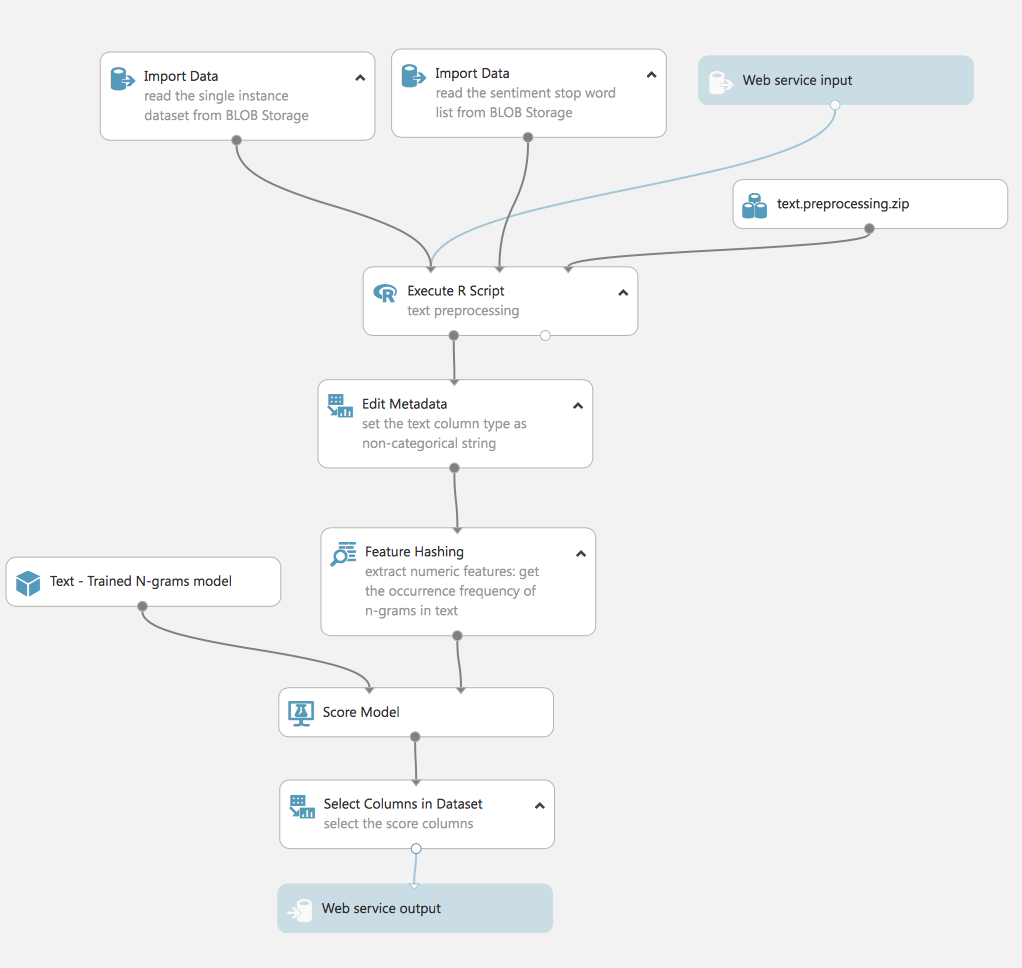
Este experimento utiliza un modelo entrenado por el proceso TF. Para los datos reales, repetimos los mismos pasos que para el proceso de preparación de los datos de entrenamiento: limpieza de datos, extracción de características, filtro.
Por lo tanto, cabe destacar que el experimento tiene 3 entradas: los datos para la prueba (1 línea del conjunto de datos original), el conjunto de datos con palabras de parada para preparar el texto (ya lo utilizamos en experimentos anteriores) y la entrada del servicio web.
La entrada del Servicio Web y la salida del Servicio Web es exactamente lo que convierte nuestro experimento en un proyecto real disponible para su uso. Al cambiar el experimento a la vista de servicio web, podemos desplegar el experimento y hacerlo disponible desde fuera de Studio.
Profundizando
En esta parte del artículo, hemos echado un breve vistazo al ejemplo de creación de un modelo y nos hemos familiarizado con los pasos más importantes del ML: la preparación de los datos, la selección del rasgo, el entrenamiento del modelo (selección de los parámetros del modelo) y la evaluación final de los resultados (AUC, Precisión, Recall, etc. )
En la siguiente parte, consideraremos el proceso de creación de un modelo para resolver un problema real, sobre datos reales y para ser aplicado en un proyecto real.


