
En la primera parte del artículo, revisamos brevemente dos populares servicios de búsqueda como servicio: Microsoft (MS) Azure Search y Elasticsearch. En esta parte, mostraremos en la práctica cómo trabajar con algunas características de uso común de Azure Search en el ejemplo de la búsqueda en el restaurante.
Visión general del portal Azure y creación del recurso Azure Search
Proporcionaremos un recorrido sobre cómo crear una cuenta gratuita de Azure (con una breve descripción del propio portal de Azure), el recurso de búsqueda y cómo trabajar con ellos. MS Azure ofrece la posibilidad de crear una cuenta de prueba gratuita con un crédito de 200 dólares durante 30 días, 12 meses de servicios gratuitos populares y, por supuesto, más de 25 servicios siempre gratuitos. Para empezar a utilizarla, debe proporcionar un número de teléfono, una tarjeta de crédito o débito y un nombre de usuario de la cuenta de MS. Además, tenga en cuenta que para crear una cuenta necesita tener algo de dinero en su tarjeta, ya que puede ver una retención de verificación de un dólar en la cuenta de su tarjeta de crédito, que se elimina en un plazo de tres a cinco días. En la página “Preguntas frecuentes sobre la cuenta gratuita de Azure ” puede leer un poco más sobre los servicios prestados y las cuentas de prueba.
Tras registrarse en el portal, verá su panel de control. En la esquina superior derecha, hay una breve información sobre su cuenta (correo electrónico y avatar), haciendo clic en la cual puede revisar su configuración, información de facturación, etc. Para crear un nuevo recurso de búsqueda, debe hacer clic en la opción del menú de la izquierda “Crear un recurso”, que se encuentra en la parte superior de la lista. Al hacer clic en esta opción, verá el mercado, donde podrá encontrar el servicio necesario mediante la entrada de búsqueda. Después de seleccionar “Recurso de búsqueda Azure”, verá un formulario, con los siguientes campos:
- URL – es necesario proporcionar un nombre de servicio, que también forma parte del punto final de la URL contra el que se emiten las llamadas a la API. Por ejemplo, nuestro endpoint de prueba será https://intro.search.windows.net, por lo que en el campo URL se introdujo “intro”.
- Suscripción – seleccione la suscripción necesaria (puede tener más de una). Si crea una cuenta de prueba gratuita, entonces verá seleccionada la suscripción “Free Trial”. Azure Search puede autodetectar Azure Table and Blob storage, SQL Database y Azure Cosmos DB para la indexación, pero sólo para los servicios dentro de la misma suscripción
- Grupo de recursos es una colección de servicios y recursos de Azure utilizados conjuntamente. Por ejemplo, si utiliza Azure Search para indexar una base de datos SQL, ambos servicios formarán parte del mismo grupo de recursos. Si acaba de crear una cuenta, entonces puede hacer clic en el botón “Crear nuevo” debajo del campo y crear el grupo de recursos introduciendo un nombre.
- Ubicación, es donde se alojará un servicio Azure. Y para futuras referencias, debe tener en cuenta que los precios pueden diferir según la geografía y, si está planeando utilizar la búsqueda cognitiva, debe elegir una región con disponibilidad de funciones.
- Nivel de precios – actualmente se ofrecen los niveles de precios Free, Basic y Standard. Cada uno de ellos tiene su propia capacidad y límites. Para este ejemplo, elegiremos el nivel de precios “Gratuito”, que está limitado a tres índices, tres fuentes de datos y tres indexadores. Para futuras necesidades, hay que recordar que un nivel de precios no puede cambiarse una vez creado el servicio. Si más adelante necesita un nivel superior o inferior, tendrá que volver a crear el servicio. Consulte la guía “Elegir un nivel de precios o SKU para Azure Search” del sitio oficial para obtener más información
En las capturas de pantalla de abajo se muestra un breve proceso de creación: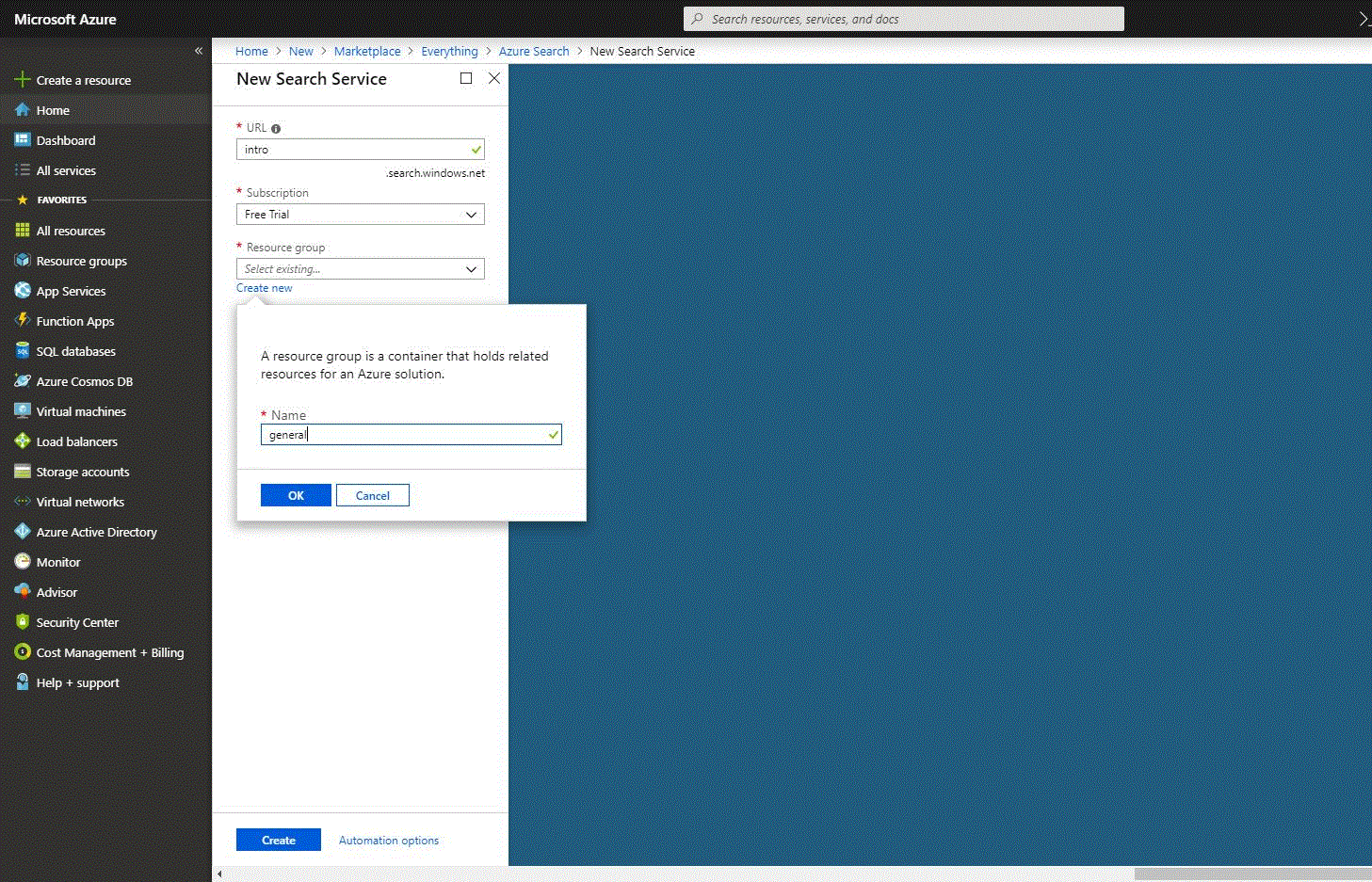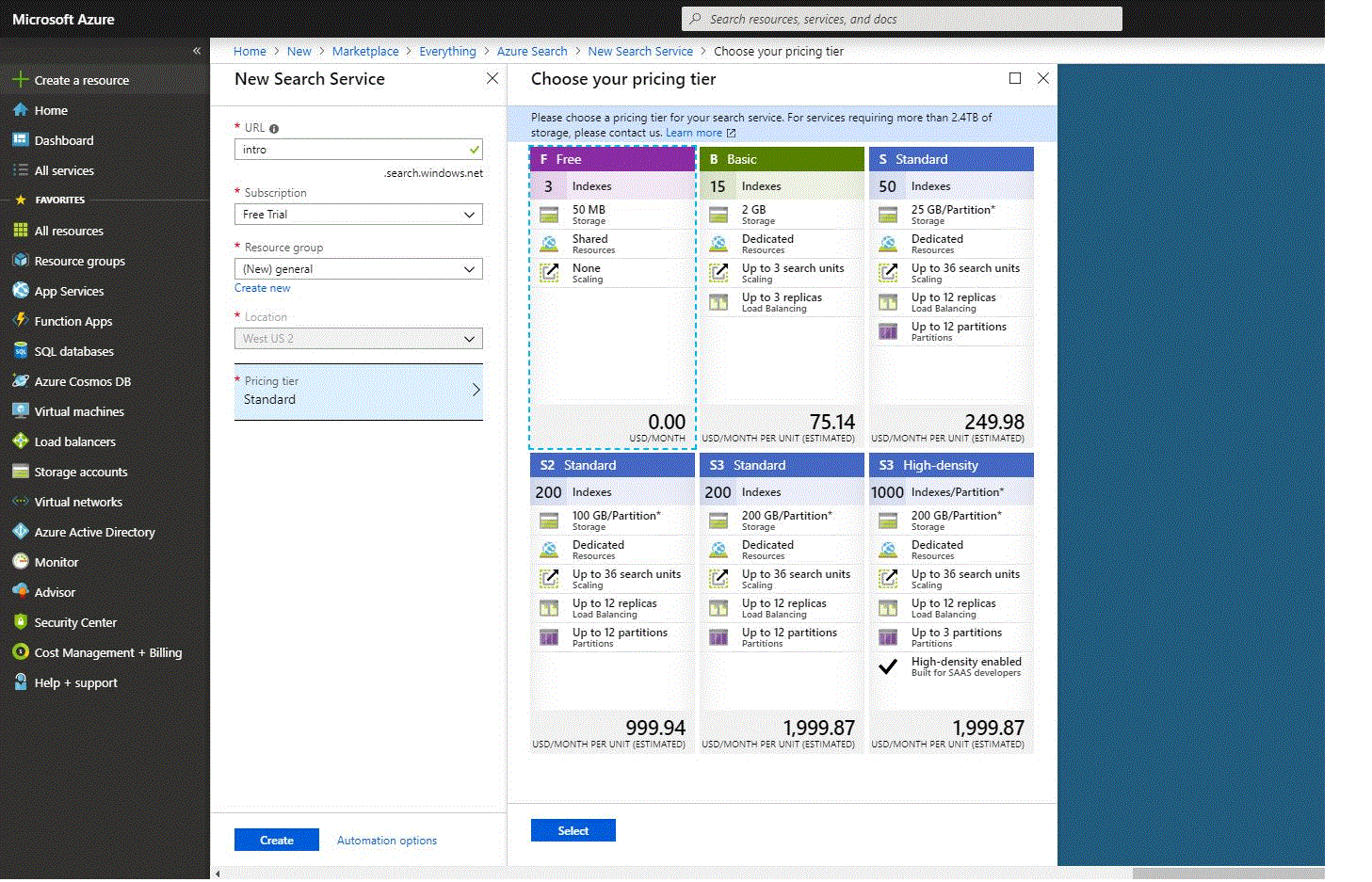
Tras pulsar el botón “Crear”, verá el recurso creado. Haga clic en él para obtener información detallada, como se muestra a continuación: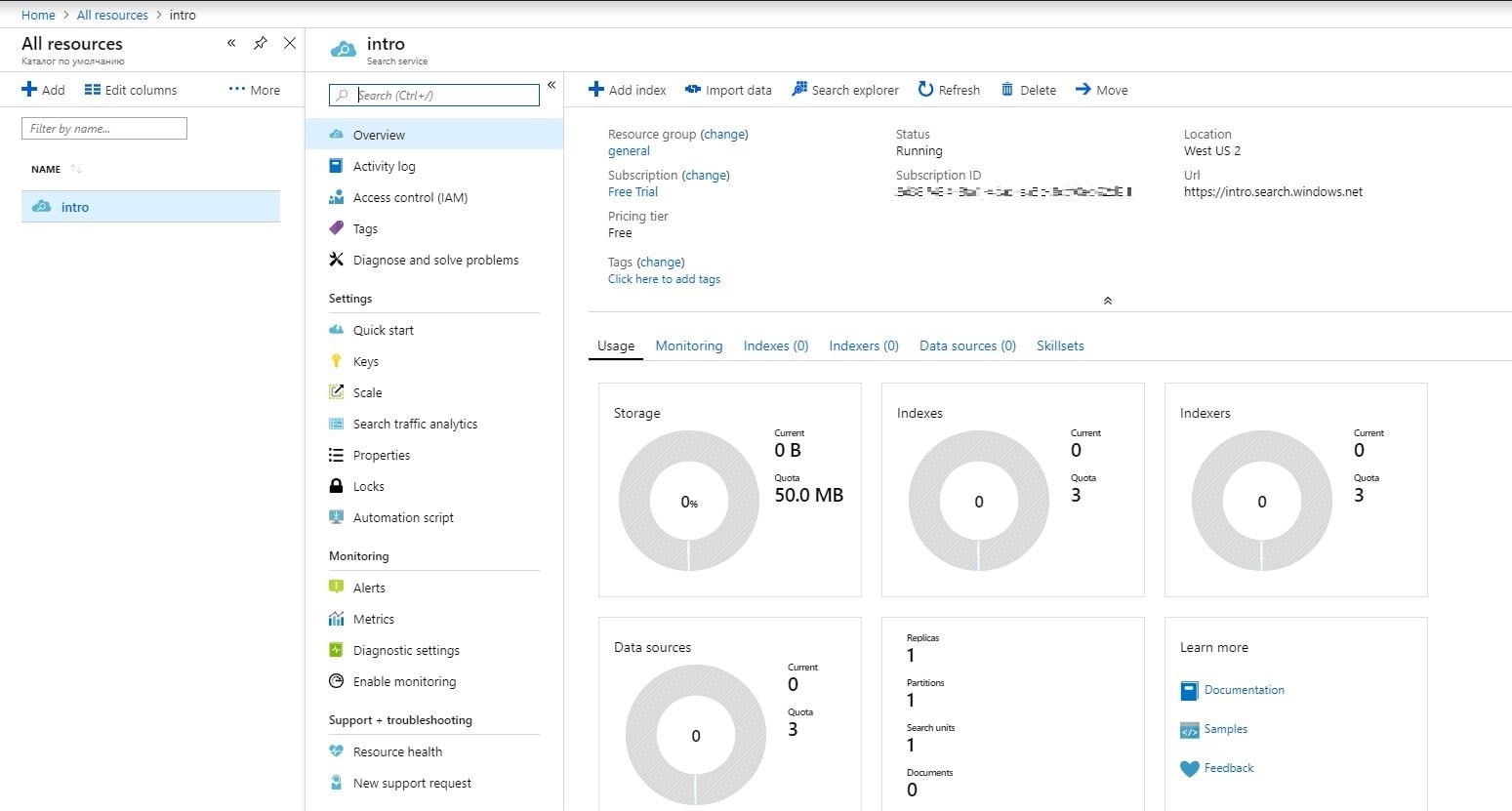
En la página de resumen del servicio, puede localizar el punto final de la URL, la información de uso, los registros de actividad, las claves y mucha otra información útil. También necesita sus claves, que puede encontrar haciendo clic en la sección “Claves” del panel de navegación. Al crear nuestro proyecto de prueba, tendrá que copiar una de las claves de administrador (son equivalentes), ya que es necesaria para crear, actualizar y eliminar objetos en el servicio
Así pues, creemos el proyecto y empecemos a explorar la funcionalidad de Azure Search. Iremos añadiendo nuevas funciones gradualmente para ir revisando todos los pasos y lograr una máxima comprensión de lo que se hace.
Creación del proyecto y del índice
La funcionalidad de Azure Search se expone a través de una API REST o un SDK .NET. En este ejemplo, utilizaremos el SDK .NET de Azure Search, que es compatible con las aplicaciones orientadas a .NET Framework 4.5.2 y superiores, así como a .NET Core. Puede elegir el que más le convenga, pero en el ejemplo, crearemos un proyecto .NET Core:
- abra Visual Studio;
- haga clic en la opción de menú “Archivo”, luego seleccione las opciones “Nuevo” y “Proyecto”;
- elija el tipo “Aplicación de consola (.NET Core)”;
- introduzca el nombre del proyecto, su ubicación y haga clic en “Aceptar”.
El nombre de nuestro proyecto será “AzureSearchIntro” y aquí está la captura de pantalla del paso de creación del proyecto: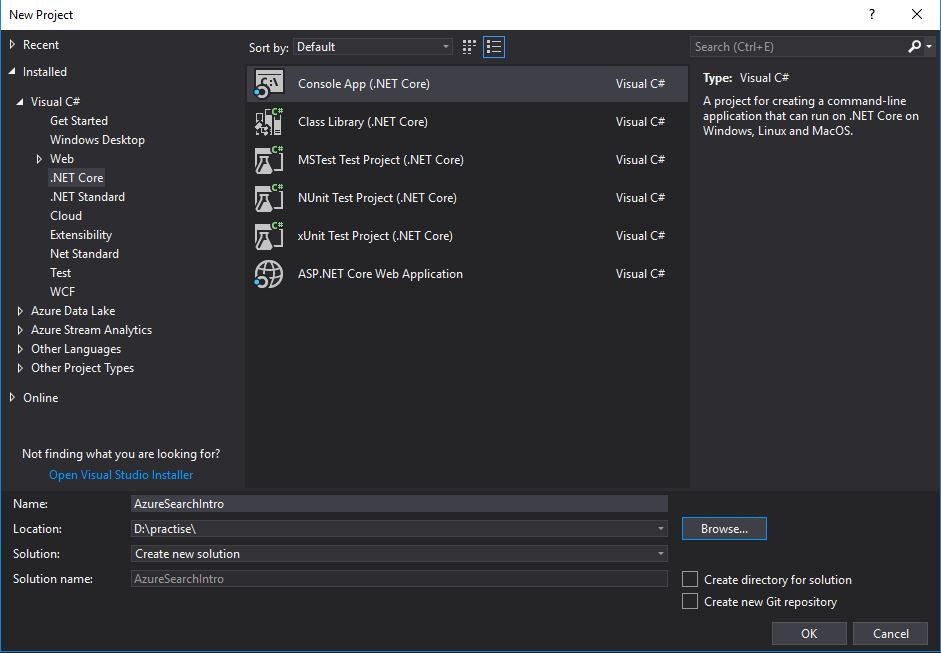
Como vamos a utilizar el SDK de .NET, ahora, necesitamos descargarlo a través del gestor de paquetes NuGet. Para ello, basta con hacer clic con el botón derecho del ratón en el nombre del proyecto, seleccionar “Gestionar paquetes NuGet…”, cambiar a la pestaña “Examinar” y buscar el paquete “Microsoft.Azure.Search”.
También añadiremos un archivo de configuración para mantener todas las claves en un solo lugar. Para ello es necesario:
- añadir los siguientes paquetes NuGet:
- Microsoft.Extensions.Configuration;
- Microsoft.Extensions.Configuration.FileExtensions;
- Microsoft.Extensions.Configuration.Json;
- crear un archivo de configuración JSON de JavaScript: haga clic con el botón derecho del ratón en el nombre del proyecto, seleccione “Añadir” y, a continuación, la opción “Nuevo elemento…”, seleccione el tipo “Archivo de configuración JSON de JavaScript” y nómbrelo (por ejemplo, “appsettings.json”);
- asegúrese de que en el archivo appsettings.json la propiedad “Copiar en el directorio de salida” esté configurada como “Copiar si es nuevo” para que la aplicación pueda acceder a él cuando se publique.
Ponga el nombre de su servicio y la clave de la API, de modo que el archivo de configuración tenga el siguiente aspecto
{
"SearchServiceName": "intro",
"SearchServiceAPIKey": "[API key]"
}
Después de esto, necesitamos crear un modelo, que representará un documento en el índice. Añada una nueva clase (haga clic con el botón derecho del ratón en el nombre del proyecto, seleccione “Añadir”, luego la opción “Nuevo elemento…”, seleccione el tipo “Clase” y nómbrela “Restaurante”). Puede introducir cualquier nombre que desee en lugar del que se muestra en el ejemplo, sólo debe tenerlo en cuenta cuando copie el código. Aquí está el código de este archivo, que usted necesita insertar:
using Microsoft.Azure.Search;
using Microsoft.Azure.Search.Models;
using Microsoft.Spatial;
using System.ComponentModel.DataAnnotations;
namespace AzureSearchIntro {
[SerializePropertyNamesAsCamelCase]
public class Restaurant {
[Key]
[IsFilterable]
public string RestaurantId { get; set; }
[IsSearchable, IsFilterable, IsSortable]
public string Name { get; set; }
[IsFilterable, IsSortable, IsFacetable]
public double? Rating { get; set; }
[IsFilterable, IsSortable]
public GeographyPoint Location { get; set; }
[IsFilterable, IsSortable, IsFacetable]
public int? WorkingHoursStart { get; set; }
[IsFilterable, IsSortable, IsFacetable]
public int? WorkingHoursEnd { get; set; }
[IsSearchable, IsFilterable, IsSortable]
public string PhoneNumber { get; set; }
}
}
Como puede ver, cada propiedad pública está decorada con atributos, cuya definición se describe a continuación:
- IsSearchable marca el campo como buscable en texto completo. Esto también significa que pasará por un análisis como el de romper palabras durante la indexación, por ejemplo, si establece un campo buscable con un valor como “azure search”, internamente se dividirá en dos tokens individuales “azure” y “search”.
- IsFilterable permite que el campo sea referenciado en las consultas de filtrado. Este atributo difiere de IsSearchable en la forma en que se manejan las cadenas. Los campos filtrables de tipo Edm.String o Collection(Edm.String) no se someten a la separación de palabras, por lo que las comparaciones son sólo para coincidencias exactas. Por ejemplo, si establece el valor de un campo de este tipo como “azure search”, y luego filtra por ‘azure’, no se encontrarán coincidencias, pero si filtra por ‘azure search’ sí aparecerán coincidencias.
- IsSortable indica si el campo puede utilizarse en expresiones OrderBy. Por defecto, el sistema ordena los resultados por puntuación, pero según las experiencias, los usuarios querrán ordenar por campos en los documentos. Los campos de tipo Collection(Edm.String) no pueden ser ordenables.
- IsFacetable se utiliza normalmente en una presentación de resultados de búsqueda que incluye el recuento de aciertos por categoría. Esta opción no puede utilizarse con campos de tipo Edm.GeographyPoint
Puede leer más información sobre los atributos en la documentación oficial. Además, recuerde que la longitud de los campos Edm.String filtrables, clasificables o factibles no puede ser superior a 32 kilobytes. Esto se debe a que dichos campos se tratan como un único término de búsqueda, y la longitud máxima de un término en Azure Search es de 32K kilobytes. Puede almacenar más texto en un solo campo de cadena si se excluye del índice. El campo se cuenta como excluido cuando no tiene atributos filtrables, ordenables y factibles (o en la API REST se establecen explícitamente en falso). Esto es útil para los campos que no se utilizan en las consultas pero que son necesarios en los resultados de las búsquedas. Excluir los campos del índice también mejora el rendimiento.
El atributo `SerializePropertyNamesAsCamelCase` en realidad indica al SDK que mapee los nombres de las propiedades a camel-case automáticamente. Garantiza que los nombres de propiedades en mayúsculas en la clase del modelo se mapeen a nombres de campos en mayúsculas en el índice.
Al diseñar las clases modelo para mapearlas a un índice de Azure Search, la recomendación oficial de Microsoft es declarar las propiedades de tipos de valor como bool e int como anulables. Si no utiliza una propiedad anulable, deberá garantizar que ningún documento de su índice contenga un valor nulo para el campo correspondiente. Por ejemplo, todos los tipos son anulables en Azure Search, por lo que cuando añada un nuevo campo de tipo Edm.Int32 a un índice existente, tras actualizar la definición del índice, todos los documentos tendrán un valor nulo para ese nuevo campo. Si a continuación utiliza una clase de modelo con una propiedad int no anulable para ese campo, obtendrá una `JsonSerializationException` al intentar recuperar los documentos.
Ahora, actualicemos el programa principal con el siguiente código:
using Microsoft.Azure.Search;
using Microsoft.Azure.Search.Models;
using Microsoft.Extensions.Configuration;
using System;
namespace AzureSearchIntro {
class Program {
static void Main(string[] args) {
var builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
string searchServiceName = configuration["SearchServiceName"];
string apiKey = configuration["SearchServiceAPIKey"];
SearchServiceClient serviceClient = new SearchServiceClient(searchServiceName, new SearchCredentials(apiKey));
if (!serviceClient.Indexes.Exists("restaurants")) {
var restaurantsIndex = new Index() {
Name = "restaurants",
Fields = FieldBuilder.BuildForType()
};
serviceClient.Indexes.Create(restaurantsIndex);
}
Console.WriteLine("{0}", "Complete. Press any key to end application...\n");
Console.ReadKey();
}
}
}
Como puede ver, al principio recuperamos el nombre del servicio y la clave de la API del archivo appsettings.json y creamos un nuevo objeto `SearchServiceClient`, que permite gestionar los índices. A continuación, el Main comprueba si el índice con nombre “restaurantes” existe, y si no, lo crea. Si ejecuta este ejemplo, verá en el portal de Azure que ahora tiene 1 índice con 0 documentos y 0B de tamaño de almacenamiento.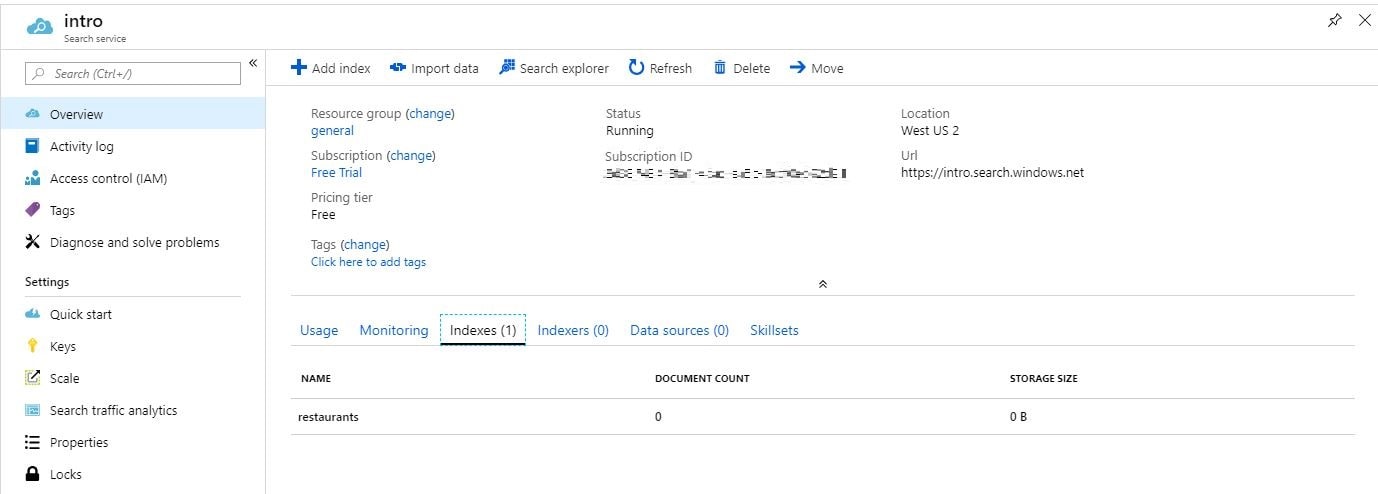
Rellenar el índice con documentos
El siguiente paso es poblar el índice con documentos. El código siguiente representa el archivo “Program.cs” y contiene el código para poblar el índice con datos de prueba:
using Microsoft.Azure.Search;
using Microsoft.Azure.Search.Models;
using Microsoft.Extensions.Configuration;
using Microsoft.Spatial;
using System;
using System.Linq;
using System.Threading;
namespace AzureSearchIntro {
class Program {
static void Main(string[] args) {
var builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
string searchServiceName = configuration["SearchServiceName"];
string apiKey = configuration["SearchServiceAPIKey"];
SearchServiceClient serviceClient = new SearchServiceClient(searchServiceName, new SearchCredentials(apiKey));
if (!serviceClient.Indexes.Exists("restaurants")) {
var restaurantsIndex = new Index() {
Name = "restaurants",
Fields = FieldBuilder.BuildForType()
};
serviceClient.Indexes.Create(restaurantsIndex);
}
ISearchIndexClient indexClient = serviceClient.Indexes.GetClient("restaurants");
if (indexClient.Documents.Count() == 0)
UploadDataToIndex(indexClient);
Console.WriteLine("{0}", "Complete. Press any key to end application...\n");
Console.ReadKey();
}
public static void UploadDataToIndex(ISearchIndexClient indexClient) {
var restaurants = new Restaurant[] {
new Restaurant() {
RestaurantId = "1",
Name = "Best restaurant",
Rating = 2.7,
WorkingHoursStart = 8,
WorkingHoursEnd = 22,
PhoneNumber = "1-800-437-4370",
Location = GeographyPoint.Create(47.679512, -122.132441)
},
new Restaurant() {
RestaurantId = "2",
Name = "Italian food",
Rating = 4.8,
WorkingHoursStart = 10,
WorkingHoursEnd = 23,
PhoneNumber = "1-800-477-4777",
Location = GeographyPoint.Create(50.496163, 30.523571)
},
new Restaurant() {
RestaurantId = "3",
Name = "Chinese food",
Rating = 4.9,
WorkingHoursStart = 7,
WorkingHoursEnd = 23,
PhoneNumber = "1-800-480-4800",
Location = GeographyPoint.Create(50.447258, 30.526541)
}
};
var batch = IndexBatch.MergeOrUpload(restaurants);
try {
indexClient.Documents.Index(batch);
}
catch (IndexBatchException e) {
string failedDocuments = String.Join(", ", e.IndexingResults.Where(r => !r.Succeeded).Select(r => r.Key));
Console.WriteLine($"Failed to index next documents: {failedDocuments}");
}
Console.WriteLine("Indexing documents.\n");
Thread.Sleep(2000);
}
}
}
En `Main` se comprueba si el índice tiene o no documentos. Y si no, a través del método `UploadDataToIndex` se crea un array de objetos Restaurant, luego se crea un IndexBatch que contiene los documentos, y se especifica la operación que debe aplicarse al lote. A continuación, el lote se carga en el índice de Azure Search mediante el método `Documents.Index`. Tenga en cuenta que todos los números de teléfono y las coordenadas son ficticios y no pertenecen a ninguna ubicación existente. En este ejemplo, utilizamos el método `MergeOrUpload` para cargar los documentos, pero puede utilizar cualquier método adecuado de la siguiente lista:
- Upload, el documento será insertado si es nuevo y actualizado (reemplazado) si es existente. Tenga en cuenta que todos los campos se sustituyen en el caso de la actualización.
- Fusionar actualiza un documento existente con los campos especificados. Si el documento no existe, la fusión falla. Cualquier campo que se especifique en la fusión sustituirá al campo existente en el documento.
- MergeOrUpload, si el documento con la clave dada ya existe en el índice, será reemplazado, de lo contrario, será añadido.
La otra cosa que hay que notar es un bloque catch que maneja un error de indexación. El servicio Azure Search puede fallar a la hora de indexar algunos de los documentos del lote si su servicio está sometido a una gran carga. La recomendación oficial de Microsoft es manejar este caso y reintentar la indexación de los documentos fallidos, o hacer algo más dependiendo de sus necesidades, por ejemplo, al menos escribir en el archivo de registro
Búsqueda de documentos
El último paso, y el más interesante, es la búsqueda de documentos en el índice. Actualice el archivo “Program.cs” con el siguiente código:
using Microsoft.Azure.Search;
using Microsoft.Azure.Search.Models;
using Microsoft.Extensions.Configuration;
using Microsoft.Spatial;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading;
using System.Threading.Tasks;
namespace AzureSearchIntro {
class Program {
static void Main(string[] args) {
var builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
string searchServiceName = configuration["SearchServiceName"];
string apiKey = configuration["SearchServiceAPIKey"];
SearchServiceClient serviceClient = new SearchServiceClient(searchServiceName, new SearchCredentials(apiKey));
if (!serviceClient.Indexes.Exists("restaurants")) {
var restaurantsIndex = new Index() {
Name = "restaurants",
Fields = FieldBuilder.BuildForType()
};
serviceClient.Indexes.Create(restaurantsIndex);
}
ISearchIndexClient indexClient = serviceClient.Indexes.GetClient("restaurants");
if (indexClient.Documents.Count() == 0)
UploadDataToIndex(indexClient);
Console.WriteLine("Searching...\n");
DocumentSearchResult results = SearchRestaurants(indexClient).GetAwaiter().GetResult();
Console.WriteLine($"Number of results: {results.Count}\n");
foreach (var item in results.Results) {
Console.WriteLine($"Score: {item.Score}");
Console.WriteLine($"Name: {item.Document.Name}");
Console.WriteLine($"Rating: {item.Document.Rating}");
Console.WriteLine($"WorkingHoursStart: {item.Document.WorkingHoursStart}");
Console.WriteLine($"WorkingHoursEnd: {item.Document.WorkingHoursEnd}");
Console.WriteLine($"PhoneNumber: {item.Document.PhoneNumber}");
Console.WriteLine("------------------------");
}
Console.WriteLine("Complete. Press any key to end application...\n");
Console.ReadKey();
}
public static void UploadDataToIndex(ISearchIndexClient indexClient) {
var restaurants = new Restaurant[] {
new Restaurant() {
RestaurantId = "1",
Name = "Best restaurant",
Rating = 2.7,
WorkingHoursStart = 8,
WorkingHoursEnd = 22,
PhoneNumber = "1-800-437-4370",
Location = GeographyPoint.Create(47.679512, -122.132441)
},
new Restaurant() {
RestaurantId = "2",
Name = "Italian food",
Rating = 4.8,
WorkingHoursStart = 10,
WorkingHoursEnd = 23,
PhoneNumber = "1-800-477-4777",
Location = GeographyPoint.Create(50.496163, 30.523571)
},
new Restaurant() {
RestaurantId = "3",
Name = "Chinese food",
Rating = 4.9,
WorkingHoursStart = 7,
WorkingHoursEnd = 23,
PhoneNumber = "1-800-480-4800",
Location = GeographyPoint.Create(50.447258, 30.526541)
}
};
var batch = IndexBatch.MergeOrUpload(restaurants);
try {
indexClient.Documents.Index(batch);
}
catch (IndexBatchException e) {
string failedDocuments = String.Join(", ", e.IndexingResults.Where(r => !r.Succeeded).Select(r => r.Key));
Console.WriteLine($"Failed to index next documents: {failedDocuments}");
}
Console.WriteLine("Indexing documents.\n");
Thread.Sleep(2000);
}
public static async Task> SearchRestaurants(ISearchIndexClient indexClient) {
List resultsList = new List();
var parameters = new SearchParameters();
parameters.Filter = "rating gt 4 and (geo.distance(location, geography'POINT(30.521541 50.444158)') le 30)";
parameters.OrderBy = new[] { "rating desc" };
parameters.QueryType = QueryType.Full;
parameters.SearchMode = SearchMode.All;
parameters.IncludeTotalResultCount = true;
parameters.Top = 10;
string azureSearch = $"(name:(('/.*food.*/'))) || (name:(('/.*Chinese.*/')))";
try {
var docResults = await indexClient.Documents.SearchAsync(azureSearch, parameters);
return docResults;
}
catch (Exception e) {
}
return null;
}
}
}
The following example will return the next search results after running:
Searching...
Number of results: 2
Score: 1.4142135
Name: Chinese food
Rating: 4.9
WorkingHoursStart: 7
WorkingHoursEnd: 23
PhoneNumber: 1-800-480-4800
------------------------
Score: 0.35355338
Name: Italian food
Rating: 4.8
WorkingHoursStart: 10
WorkingHoursEnd: 23
PhoneNumber: 1-800-477-4777
------------------------
Complete. Press any key to end application...
Revisemos en detalle el método “BuscarRestaurantes”. Una consulta acepta varios parámetros que proporcionan los criterios de consulta y también especifican el comportamiento de la búsqueda:
- Las expresiones defiltro restringen la búsqueda a campos específicos o añaden criterios de coincidencia. Pueden ejecutarse de forma independiente como una consulta totalmente expresada, o aclarar una consulta que tenga parámetros adicionales. Revisaremos las expresiones de filtro más adelante, debajo de la descripción de los parámetros de búsqueda.
- El parámetroOrderBy acepta una lista de los criterios de ordenación, donde cada uno de los criterios puede ser el nombre de un campo ordenable, una llamada a las funciones geo.distance o search.score. Puede utilizar asc (orden por defecto) o desc para especificar el orden de clasificación. El orden de las expresiones determina el orden de clasificación final.
- QueryType especifica qué analizador debe utilizarse. Puede ser de dos tipos:
- el analizador de consultas simple por defecto, que es óptimo para la búsqueda de texto completo (`QueryType.Simple`);
- el analizador de consultas completo de Lucene, que se utiliza para construcciones de consulta avanzadas como expresiones regulares, búsqueda por proximidad, búsqueda difusa y con comodines, etc. (`QueryType.Full`).
- SearchMode indica si debe coincidir alguno (opción por defecto “SearchMode.Any”) o todos (“SearchMode.All”) de los términos de búsqueda para contar el documento como coincidencia.
- IncludeTotalResultCount especifica si el recuento total de resultados es necesario o no en la respuesta. El valor por defecto es falso
- Top especifica cuántos elementos deben ser devueltos. También puede utilizarse con el parámetro “Skip” para la paginación, que especifica cuántos elementos deben saltarse.
- SearchFields es un parámetro opcional y se utiliza para restringir la búsqueda a campos específicos. Así, puede sustituir la variable azureSearch, mostrada anteriormente, por las siguientes líneas de código:
parameters.SearchFields = new[] { "nombre" };
string azureSearch = $"('/.*comida.*/') || ('/.*chino.*/')";
El parámetro filtro es la base de varias experiencias de búsqueda, como la búsqueda por geolocalización, la navegación facetada, etc. Como se ha mencionado anteriormente en el texto, revisamos la lista de operadores de filtro que se pueden utilizar:
- operadores lógicos (`and`, `or`, `not`).
- Expresiones de comparación:
- `eq` – iguales;
- `ne` – no es igual;
- `gt` – mayor que;
- `lt` – menor que;
- `ge` – mayor que o igual;
- `le` – menos que o igual.
- Constantes de los tipos admitidos y referencias a nombres de campos (con el atributo Filterable);
- `any` y `all`. Ambas son compatibles con los campos de tipo `Collection(Edm.String)` pero pueden utilizarse con expresiones diferentes:
- `any` sólo puede utilizarse con expresiones de igualdad simples o con una función `search.in`;
- `todos` sólo puede utilizarse con expresiones de desigualdad simples o con una función `no buscar.in`.
- Las funciones geoespaciales `geo.distance` y `geo.intersects`, que se utilizan para los controles de búsqueda “cerca de mí” o basados en mapas.
- La función `search.in`, que comprueba si un campo de cadena dado es igual a uno de una lista de valores dada.
- La función `search.ismatch`, que evalúa la consulta de búsqueda como parte de una expresión de filtro y devuelve todos los documentos que coinciden con esta consulta.
- La función `search.ismatchscoring` es bastante similar a la función `search.ismatch`. La única diferencia es que la puntuación de relevancia de los documentos que coincidan con la consulta `search.ismatchscoring` repercutirá en la puntuación global del documento, mientras que en el caso de `search.ismatch`, la puntuación del documento no se modificará.
Puede leer más sobre los entresijos de cada uno de los parámetros descritos en la documentación oficial.
Lo último, pero no menos interesante, que vamos a discutir es el refuerzo de términos. Clasifica un documento más alto si contiene el término potenciado, en relación con los documentos que no contienen el término. Se diferencia de los perfiles de puntuación en que los perfiles de puntuación potencian determinados campos, no términos específicos. Para potenciar un término es necesario utilizar el símbolo “^” con un factor de potenciación (un número) al final del término que se busca. Cuanto mayor sea el factor de potenciación, más relevante será el término en relación con otros términos de búsqueda. Por defecto, el factor de refuerzo es 1. Puede ser inferior a 1, pero nunca un valor negativo. El siguiente ejemplo ayuda a ilustrar el uso de la potenciación de términos. Actualice el método `BuscarRestaurantes` con el siguiente código:
public static async Task> SearchRestaurants(ISearchIndexClient indexClient) {
List resultsList = new List();
var parameters = new SearchParameters();
parameters.Filter = "rating gt 1";
parameters.QueryType = QueryType.Full;
parameters.SearchMode = SearchMode.All;
parameters.IncludeTotalResultCount = true;
parameters.Top = 10;
string azureSearch = $"(name:food^2) || (name:restaurant)";
try {
var docResults = await indexClient.Documents.SearchAsync(azureSearch, parameters);
return docResults;
}
catch (Exception e) {
}
return null;
}
Verá que los siguientes resultados serán devueltos después de la ejecución:
Searching...
Number of results: 3
Score: 0.30778623
Name: Italian food
Rating: 4.8
WorkingHoursStart: 10
WorkingHoursEnd: 23
PhoneNumber: 1-800-477-4777
------------------------
Score: 0.30778623
Name: Chinese food
Rating: 4.9
WorkingHoursStart: 7
WorkingHoursEnd: 23
PhoneNumber: 1-800-480-4800
------------------------
Score: 0.07599751
Name: Best restaurant
Rating: 2.7
WorkingHoursStart: 8
WorkingHoursEnd: 22
PhoneNumber: 1-800-437-4370
------------------------
Complete. Press any key to end application...
Como puede ver, los documentos que tienen el término potenciado “comida” están en la parte superior de los resultados. Si elimina el término boost, la variable azureSearch tendrá el siguiente aspecto
string azureSearch = $"(name:food) || (name:restaurant)";
Searching...
Number of results: 3
Score: 0.35786763
Name: Best restaurant
Rating: 2.7
WorkingHoursStart: 8
WorkingHoursEnd: 22
PhoneNumber: 1-800-437-4370
------------------------
Score: 0.18116833
Name: Italian food
Rating: 4.8
WorkingHoursStart: 10
WorkingHoursEnd: 23
PhoneNumber: 1-800-477-4777
------------------------
Score: 0.18116833
Name: Chinese food
Rating: 4.9
WorkingHoursStart: 7
WorkingHoursEnd: 23
PhoneNumber: 1-800-480-4800
------------------------
Complete. Press any key to end application...
La potenciación de términos puede ser útil cuando se quiere implementar una búsqueda, dentro de la cual el usuario podrá introducir unas cuantas palabras separadas y el orden de estas palabras mostrará la relevancia de cada una de ellas. Por ejemplo, si el usuario en el sitio de cine introduce “horror, thriller, drama” en el cuadro de búsqueda, con el refuerzo de términos en la parte superior de los resultados aparecerán las películas de horror, luego los thrillers y después los dramas.
Y eso no es ni la mitad…
En este artículo, hemos revisado en la práctica un par de los usos más comunes de Azure Search. La funcionalidad proporcionada es mucho más amplia y, esperamos, que al leer, haya comprendido los principios básicos de uso y se haya inspirado para seguir estudiando.
Acerca de Redwerk
Nuestra empresa está especializada en el desarrollo de software a medida para sectores como el comercio electrónico, la automatización de negocios, la sanidad electrónica, los medios de comunicación y el entretenimiento, la administración electrónica, el desarrollo de juegos, las startups y la innovación. Una de las tecnologías que utilizamos y proporcionamos a las empresas es el desarrollo de aplicaciones Azure. Nuestro equipo de desarrollo dedicado ya ha entregado docenas de soluciones exitosas a través de la tecnología Azure. Revele el poder de las plataformas SaaS con nosotros.


