Sports Events Crawler




El cliente es una empresa que ofrece soluciones profesionales de software deportivo.
Todos los clientesDesarrollo del producto
Redwerk ha creado desde cero esta solución automatizada de rastreo de torneos deportivos. Nuestro equipo de profesionales ha trabajado en todas las fases del proceso: análisis, diseño, desarrollo, pruebas, despliegue, mantenimiento y soporte.
Más informaciónMinería de datos
Realizamos scraping de sitios web y API de redes sociales como big data tras su procesamiento automático para devolver los sitios web archivados a los usuarios.
Más informaciónDesafío
La empresa cliente proporciona los conocimientos necesarios para ayudar a los operadores deportivos a atraer eventos como torneos locales, regionales y nacionales. Aunque sus soluciones de software personalizadas utilizan tecnología punta, no todos los pasos del proceso estaban optimizados. La búsqueda y adquisición de datos, por ejemplo, se basaba en un proceso totalmente manual y, por tanto, necesitaba una revisión drástica. Todas las tareas de búsqueda, almacenamiento y procesamiento de datos debían realizarse manualmente, lo que sólo resultaba eficaz hasta alcanzar una determinada cantidad de datos. Por tanto, era necesario automatizar este flujo de trabajo, y ahí es donde entraron en escena los expertos en software flexible de Redwerk.
Nuestra tarea consistía en automatizar el algoritmo manual original utilizado por el cliente, que estaba estructurado más o menos de la siguiente manera:
- Búsqueda de términos clave.
- Recopilación de especificaciones de búsqueda y resultados: término de búsqueda, fecha de búsqueda, página de la búsqueda, título, URL, tipo, fragmento, imagen de caché, detalles de caché.
- Extracción de la información más importante de los fragmentos, títulos, URL, etc. Asignarlos al resultado de búsqueda asociado.
- Reconocimiento y clasificación en categorías de los datos extraídos.
En pocas palabras: Se encargó a Redwerk el desarrollo de una solución que combinara la búsqueda automatizada y el rastreo de páginas web. Además, se nos pidió que creáramos una solución de almacenamiento de datos para poder clasificar la información y realizar consultas.
Para el usuario final, esto significa que el software facilita la búsqueda de torneos y eventos, así como la obtención de toda la información pertinente sobre torneos y datos de contacto.
Nuestra investigación
Redwerk se enfrentó a una tarea difícil porque toda la información debía encontrarse, analizarse y estructurarse automáticamente. Esto dificultaba la aplicación de enfoques deterministas para la rápida recuperación de la información. Los métodos de análisis necesarios habrían sido muy complejos de aplicar, y pronto se hizo evidente que los algoritmos deterministas no eran adecuados para procesar páginas de estructuras aleatorias.
Sólo si modificamos el punto de partida inicial suponiendo que existe un número finito de fuentes de las que hay que extraer información, dicho enfoque se justifica por su relativa sencillez y determinación. A pesar de que la extracción de información aleatoria es una tarea muy interesante y puede aportar algunas ventajas, para esta solución técnica concreta no parecía adecuada. Si la aplicación no era capaz de garantizar la búsqueda de una determinada cantidad de datos con gran precisión, no serviría de nada.
El equipo de Redwerk evaluó varios enfoques para este reto de software.
Minería de datos
Este método habría sido una automatización directa del flujo de trabajo existente del cliente. Para extraer datos, este método requería analizar, comprender y entrelazar partes del lenguaje natural. Mientras que los humanos ven sustantivos, verbos, nombres, direcciones, etc. en una página web, las máquinas sólo ven cadenas y números. Construir un sistema autodidacta capaz de entender el lenguaje natural es una de las tareas más difíciles de la informática.
Incluso si consideramos un sistema mucho más simple para esta solución en particular, al que se le “enseñaría” gradualmente a recopilar datos de diferentes tipos de sitios web a través de una interfaz sencilla, este enfoque no parecía funcionar para nuestro cliente.
Ventajas:
- Solución más avanzada y prospectiva, gran cantidad de datos recogidos a lo largo del tiempo
Contras:
- Aplicación lenta
- Algoritmos complejos
- Consumo intensivo de recursos
- Solución más cara
Redes sociales
Las redes sociales son enormemente populares y tienen una audiencia masiva, razón por la cual son cada vez más populares entre los anunciantes que desean llamar la atención sobre acontecimientos específicos. Por ser la red social más popular del mundo, se eligió Facebook como objeto de nuestra investigación. Evaluamos el alcance de la publicidad de este tipo de eventos en las redes sociales, la cantidad de datos útiles que podían obtenerse y el grado de fragmentación y fiabilidad de estos datos.
Los resultados de nuestro estudio en Facebook fueron mayoritariamente positivos. Muchos torneos deportivos se anuncian en Facebook, y constantemente se añaden nuevos eventos. Gracias a la API de Facebook, es fácil recopilar y procesar datos de la red social.
Ventajas:
- Base de datos de eventos en rápido crecimiento
- Fácil recopilación y procesamiento de datos a través de la API
- Solución más fácil y rápida de implantar
Contras:
- Sin categorización de eventos
- No se especifica el deporte
- Información introducida incorrectamente (ciudad especificada como lugar del evento, por ejemplo)
Agregación de datos
Otro método para recopilar información sobre los próximos acontecimientos deportivos consiste en obtenerla de sitios web especializados en deportes. Éstas están diseñadas para proporcionar información sobre eventos relacionados con el tema de forma práctica, lo que hace que los datos obtenidos de estos sitios sean muy valiosos para los fines de nuestro cliente. Algunos disponen de sistemas de suscripción y proporcionan API para facilitar el acceso a los datos, lo que permite una rápida implementación de la recopilación y el procesamiento de datos.
Sin embargo, nuestra investigación se centró en un escenario en el que no se utilizan fuentes de datos comerciales y hay que recopilar “gratis” tantos datos como sea posible. Bajo esta premisa, habríamos tenido que desarrollar rastreadores web para descargar, analizar y extraer datos del código fuente de las páginas HTML.
Ventajas:
- La mayor cantidad de datos precisos y pertinentes
Contras:
- Se requiere un enfoque individual para cada sitio web
- Los webmasters suelen dificultar la extracción de datos
- Los costes y el tiempo de desarrollo aumentan con el número de sitios web, a menos que se utilicen API.
Nuestra solución
Teniendo en cuenta las ventajas y desventajas de los enfoques mencionados, se decidió utilizar no uno de ellos, sino una combinación de los dos últimos: el análisis de datos de Facebook y la agregación de datos. Utilizar los agregadores existentes como principal fuente de datos para obtener información sobre los próximos eventos parece ser el método más beneficioso en términos de cantidad de datos valiosos recuperados, si se aborda con cuidado. Nuestra solución personalizada también extrae información adicional de Facebook.
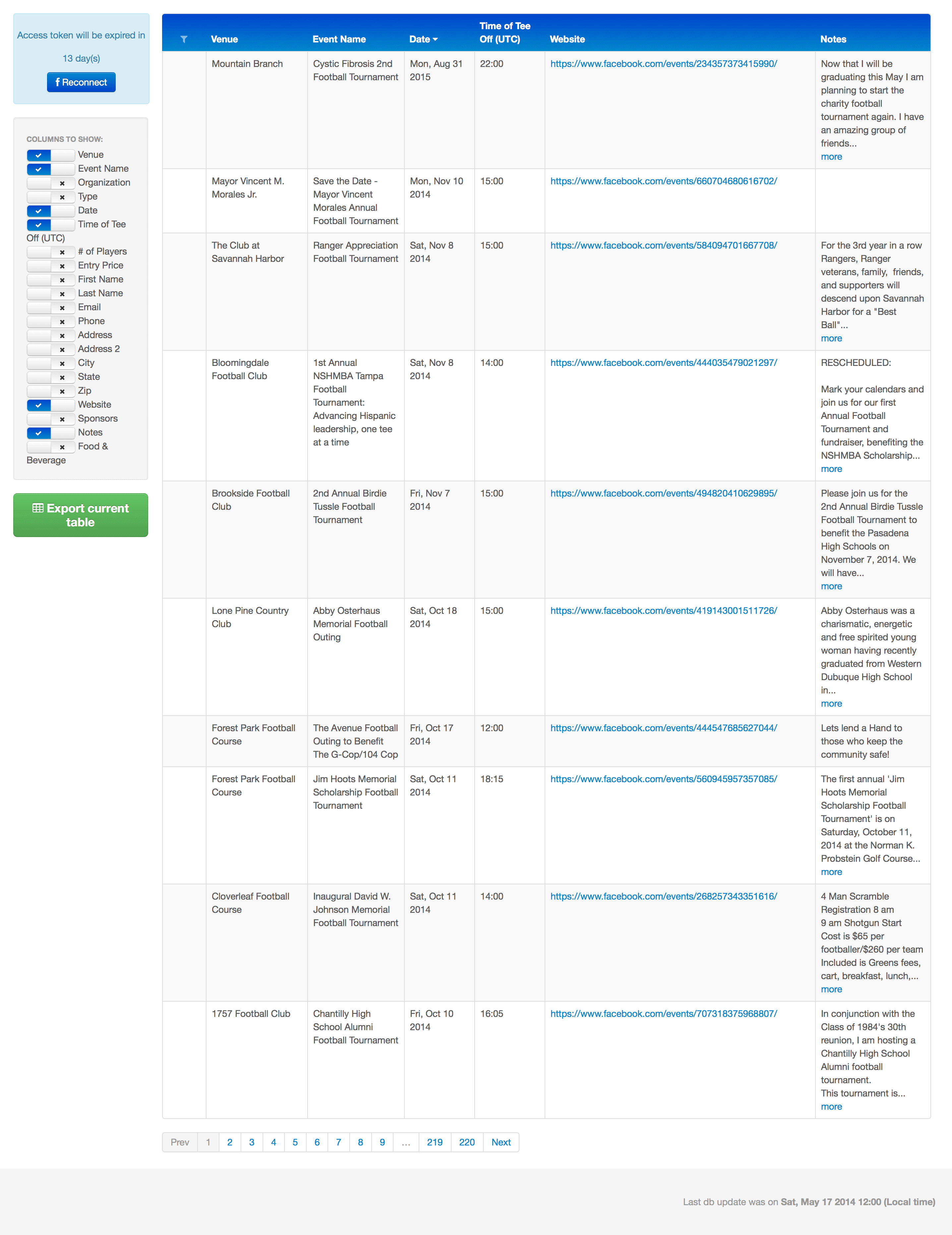
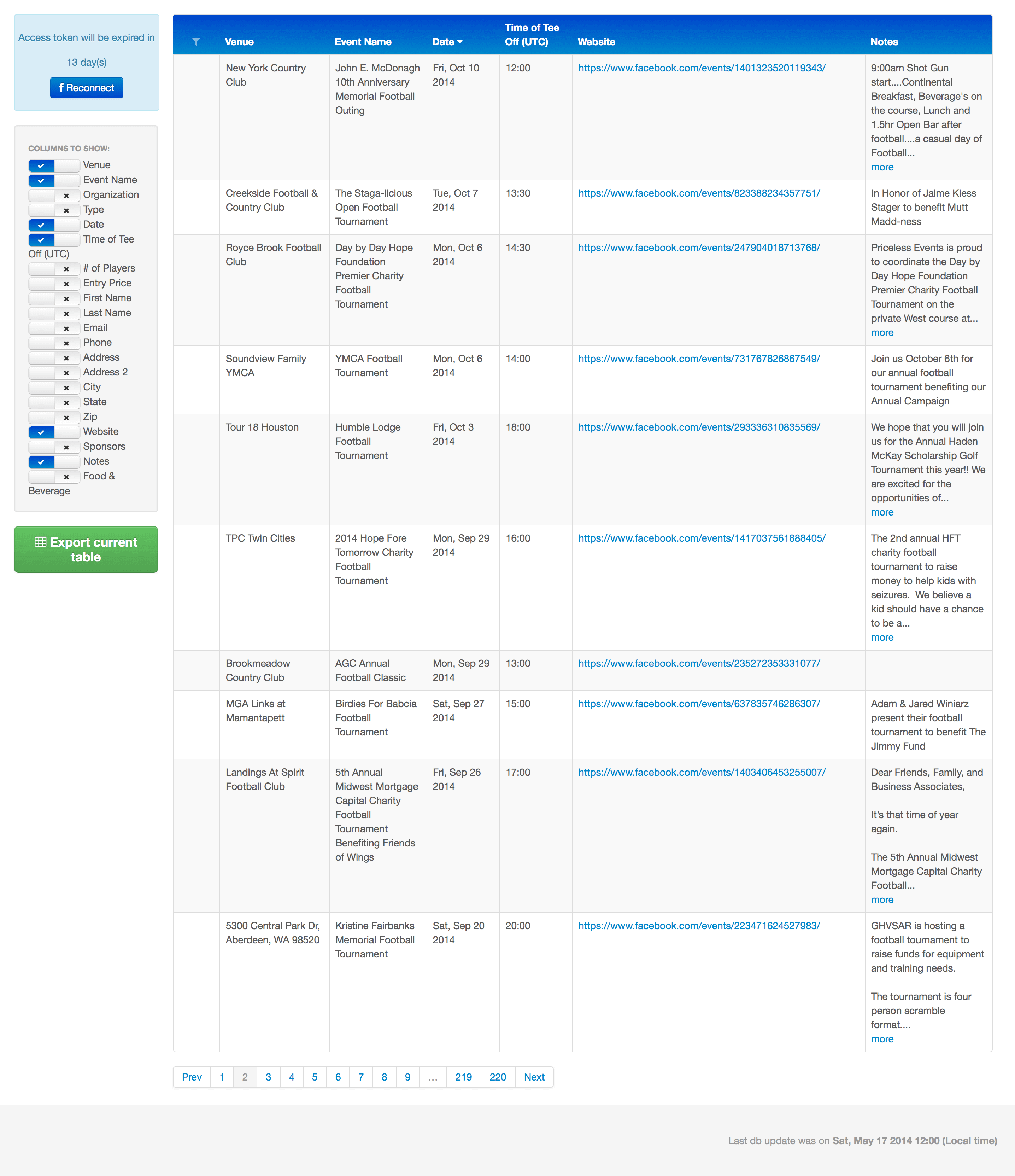
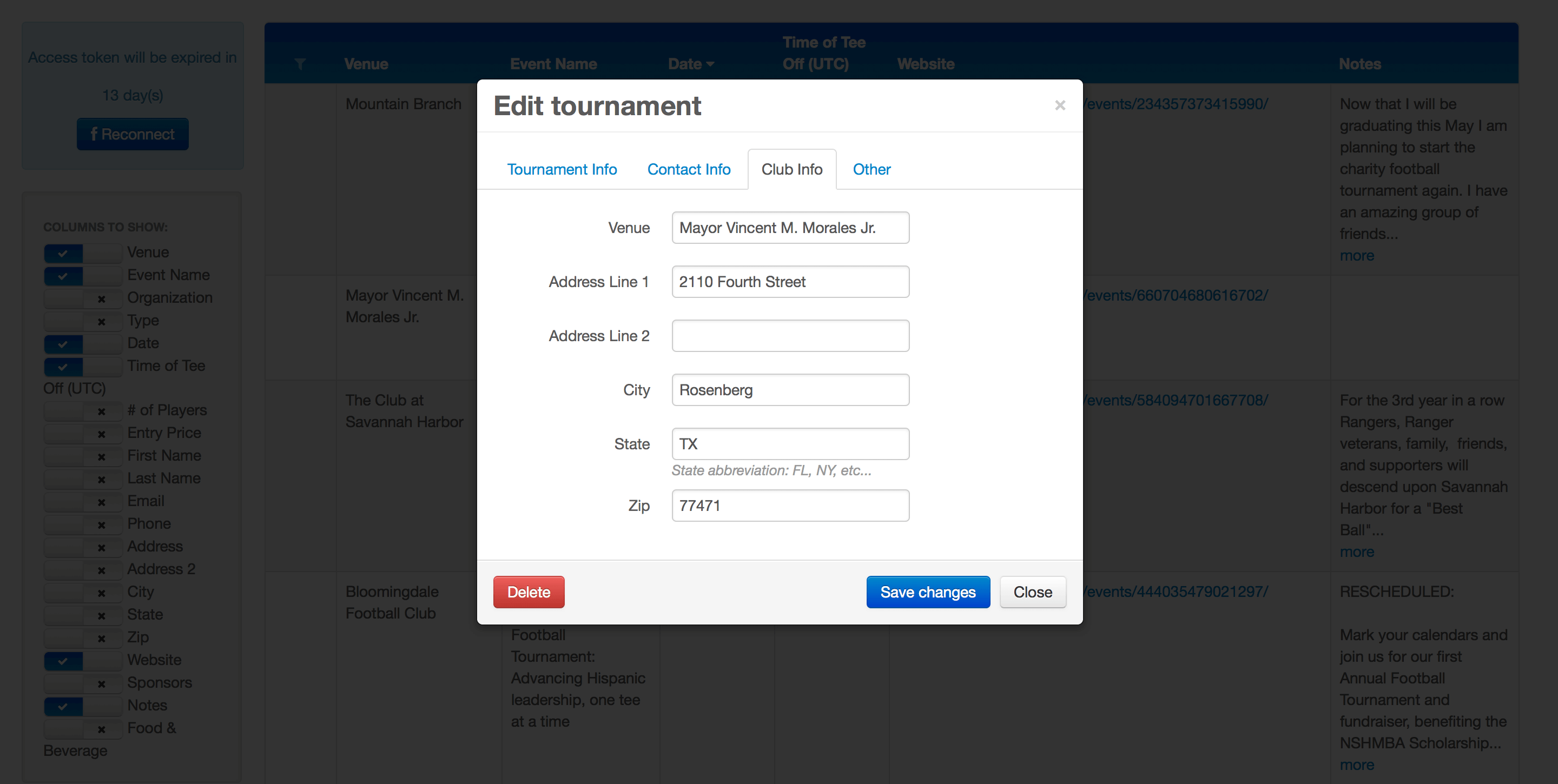
Gracias a los procesos automatizados de software de rastreo web implementados por los ingenieros de Redwerk, esta solución permite filtrar y buscar eventos deportivos según una serie de criterios diferentes. Muestra enlaces a las páginas pertinentes, de las que se obtuvo la información (páginas de eventos de Facebook) y otros tipos de información, y permite editar y/o eliminar fácilmente eventos específicos.
Resultado
El equipo de Redwerk pronto se dio cuenta de que era muy difícil, rentable y laborioso limitarse a replicar el algoritmo manual de nuestro cliente con procesos automatizados. En su lugar, nos centramos en implantar una estructura de búsqueda con un conjunto fijo de fuentes de datos, de las cuales Facebook se utilizó en el prototipo. Este tipo de sistema era mucho más fácil de implantar y mantener y cumplía perfectamente los requisitos iniciales.
Con esta solución, Redwerk consiguió ahorrar a su cliente tiempo y dinero valiosos, y nuestros ingenieros encontraron una solución elegante a un problema peliagudo, de la que muchos operadores deportivos profesionales deberían poder beneficiarse en el futuro.
¿Necesitas rastrear la web?
HablamosTecnologías
Relacionado en Blog

Scala Play vs ASP.NET Web API - Comparación de marcos web
Nuestra empresa lleva más de 12 años desarrollando software. Y alrededor de la mitad de nuestros proyectos son sistemas distribuidos multihilo de alta carga. Por lo tanto, nuestros desarrolladores utilizan las tecnologías más avanzadas y los últimos frameworks en el proceso E...
Leer más
Cómo rastrear un sitio web protegido: Una mirada en profundidad
Los rastreadores web son programas de descarga y procesamiento masivo de contenidos de Internet. También se les suele llamar "arañas", "robots" o incluso simplemente "bots" En esencia, un rastreador hace lo mismo que cualquier navegador web ordinario: envía peticiones HTTP a los ...
Leer más¿Impresionado?
ContrátenosOtros casos prácticos
PageFreezer
Desarrolló un sitio web y un SaaS de marketing en redes sociales que fue preseleccionado como finalista mundial de Red Herring Top 100
Mejora de la plataforma del Parlamento Europeo
Plataforma de voto electrónico actualizada para el Parlamento Europeo en menos de 1 mes
Adfectious
Desarrollo de un sistema de publicidad móvil inspirado en AdMob de Google y utilizado en medios de comunicación rumanos populares como meteoromania.ro