
En la primera parte de este artículo se expuso el ejemplo de la creación de un modelo y se nos familiarizó con los pasos más importantes del ML: preparación de los datos, selección del rasgo, entrenamiento del modelo (selección de los parámetros del modelo) y evaluación final de los resultados (AUC, Precisión, Recall, etc.).
Veamos ahora un ejemplo real de utilización de Studio para resolver un problema práctico de ML. Este proyecto se implementó con éxito y ya se utiliza para la predicción basada en el texto de cv/oportunidad.
Lo primero que necesitamos en el aprendizaje automático son los datos. Todos los datos necesarios para el entrenamiento se almacenan en Azure Document DB (Cosmos DB). Para mejorar el proceso de preparación de los datos y el futuro entrenamiento, obtenemos los datos y los almacenamos en un conjunto de datos en Azure ML Studio.
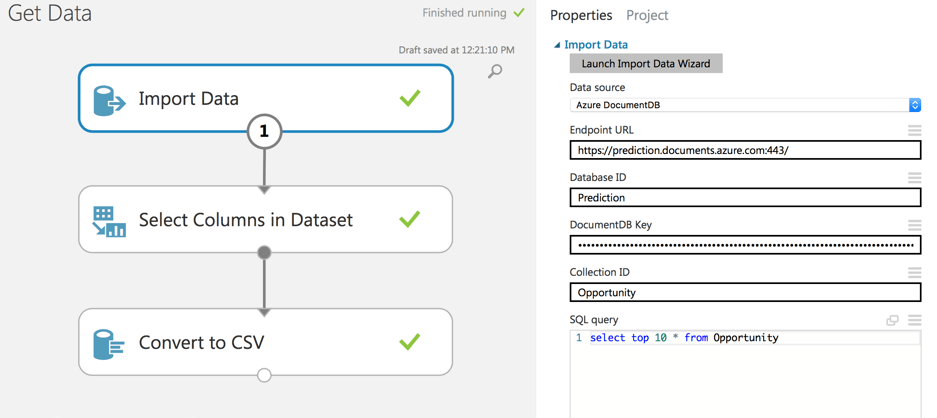
Una vez realizada la importación podemos visualizarla.
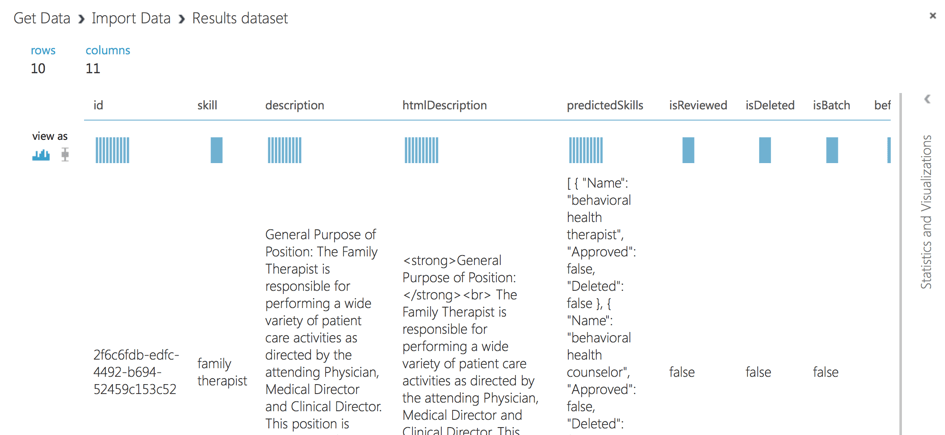
Además, como la base de datos de documentos contiene campos adicionales, debemos seleccionar campos específicos como habilidad, descripción…
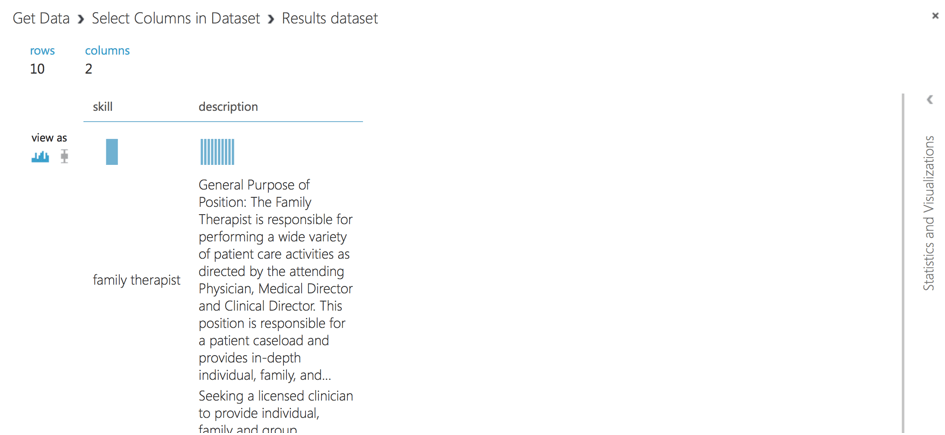
Como paso final, almacenamos el conjunto de datos como .csv en el almacenamiento de Azure ML Studio.
Un conjunto de datos suele requerir cierto preprocesamiento antes de poder ser analizado. Por ejemplo, puede que nos hayamos dado cuenta de que hay valores perdidos en las columnas de varias filas. Es necesario limpiar estos valores perdidos para que el modelo pueda analizar los datos correctamente. En este caso, eliminaremos las filas que tengan valores perdidos. A continuación, limpiamos el texto utilizando el módulo de preprocesamiento de texto. La limpieza reduce el ruido en el conjunto de datos, ayuda a encontrar las características más importantes y mejora la precisión del modelo final. Eliminamos las palabras vacías (palabras comunes como “el” o “a”), los números, los caracteres especiales, los caracteres duplicados, las direcciones de correo electrónico y las URL. También convertimos el texto a minúsculas, lematizamos las palabras y detectamos los límites de las frases que, entonces, se indican con el símbolo “”||”” en el texto preprocesado
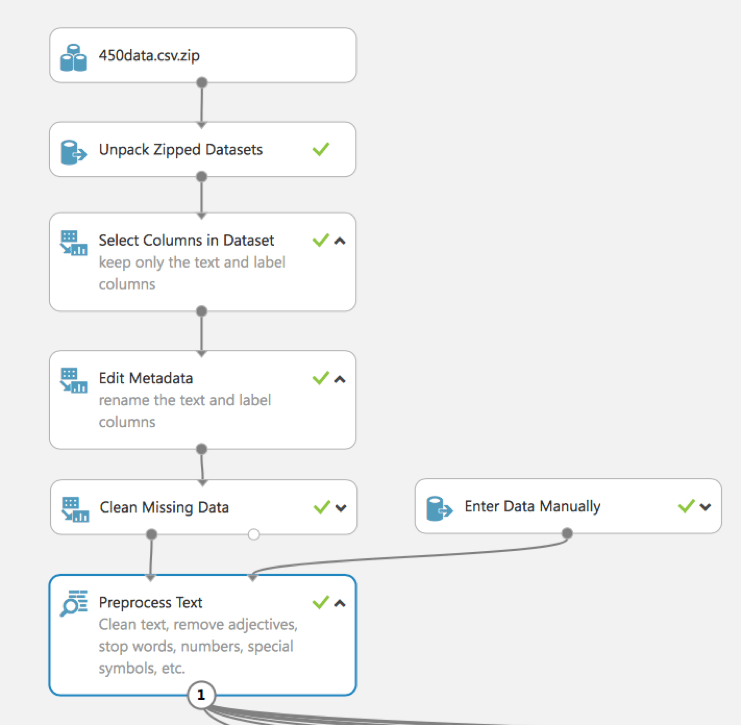
Como vemos, en este experimento (a diferencia del ejemplo de la primera parte) se utiliza el módulo integrado Preprocess Text (anteriormente mostramos el uso de un script de R). Nos permite limpiar el texto, eliminar las palabras de parada, los números, los símbolos especiales, etc.
El objetivo principal de este paso es recibir un texto limpio (descripción de la oportunidad) sin palabras de parada, números, correos electrónicos, URLs, etc. A modo de ejemplo, aquí tiene una descripción antes del preprocesamiento:
General Purpose of Position: The Family Therapist is responsible for performing a wide variety of patient care
activities as directed by the attending Physician, Medical Director andClinical Director. This position is
responsible for a patient caseload and provides in-depth individual, family, and group counseling. Counseling
includes the ongoing completion of psychosocial and bio-psychosocial assessments. The Family Therapist collaborates
with the Clinical Team to develop individualized treatment plans and assists in coordinating discharge planning.
This position follows patients' progress from a psychological standpoint, beginning with admittance through
discharge. During this time, the Family Therapist maintains frequent and open communication with the Clinical
Director and Therapists regarding any issues or problems. Primary Responsibilities (include but are not limited to):
Establish individualized family therapy programs, through face to face and/or phone communication with families of
Sunspire Health patients. Conduct and evaluate family assessments...
Y después:
purpose ||| therapist perform variety care activity as direct physician | director director ||| caseload | depth |
family | group counsel ||| counsel include completion bio | assessment ||| family therapist collaborate develop
treatment plan assist discharge plan ||| follow patient | progress standpoint | begin admittance discharge ||| |
therapist maintain communication director therapist issue problem ||| | include but limit | ||| | establish therapy
program | face face | or communication family sunspire health patient ||| | conduct evaluate assessment ||| |
conduct family counsel session patient ||| | referral resource patient | family area ||| | coordinate patient |
family patient treatment plan discharge | aftercare plan ||| | basis | coordinate lead retreat consist group therapy
| lecture question answer period | facility | finalization discharge aftercare plan ||| | participate | site
activity that relate therapy ||| | create group group sunspire health facility | focus system issue recovery ||| |
maintain documentation family counsel activity ||| | may ask complete review | utilization review | as ||| | |
college or university psychology | | or field ||| | health set ||| family therapist | | maintain licensure | lcs w |
lmh c | lmf t | aarn p. | acquire licensure ||| |license proof insurance ||| | maintain cp r aid certification ||| |
strong ||| | detail ||| | pressure as as ||| | strong | ||| | structure english language mean spell word | rule
composition | grammar ||| | principle process service ||| include assessment| standard service | evaluation
satisfaction ||| | behavior performance | difference | personality | | learn motivation | research method |
assessment treatment disorder ||| | patient | patient service resolve issue ||| | acumen ||| | car f standard ||| |
problem review develop evaluate option implement solution ||| | logic reason identify strength weakness solution |
conclusion or approach problem ||| | cost benefit action choose ||| | handle priority urgency ||| | communication | |
presentation ||| | | people ||| as||| | other | reaction | understand react ||| as | adjust action relation other |||
| bring other try reconcile difference||
Para construir un modelo para datos de texto, normalmente tenemos que convertir el texto de forma libre en vectores de características numéricas. En nuestro experimento, utilizamos el módulo Extract N-Gram Features from Text para transformar los datos de texto en dicho formato. Este módulo toma una columna de palabras separadas por espacios en blanco y calcula un diccionario de palabras, o N-gramas de palabras, que aparecen en su conjunto de datos. A continuación, cuenta cuántas veces aparece cada palabra, o N-grama, en cada registro, y crea vectores de características a partir de esos recuentos. En nuestro experimento fijamos el tamaño de los N-gramas en 2, por lo que nuestros vectores de características incluyen palabras sueltas y combinaciones de dos palabras posteriores.

Aplicamos la ponderación TF-IDF (Term Frequency Inverse Document Frequency) a los recuentos de N-gramas. Este enfoque añade el peso de las palabras que aparecen con frecuencia en un solo registro, pero que son raras en todo el conjunto de datos. Otras opciones son la ponderación binaria, TF y gráfica.
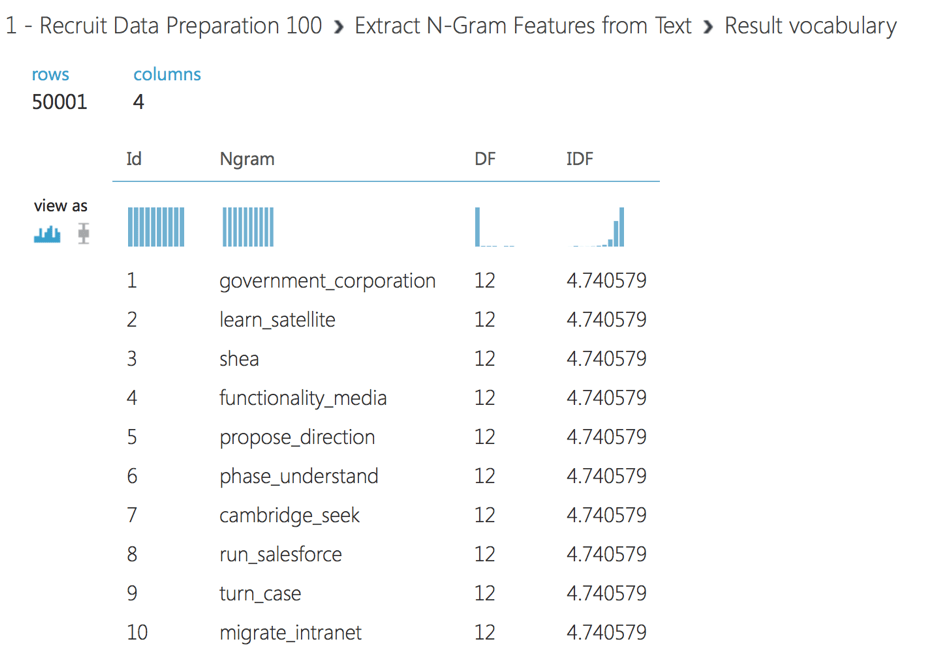
Estas características de texto suelen tener una alta dimensionalidad. Por ejemplo, si su corpus tiene 100.000 palabras únicas, su espacio de características tendrá 100.000 dimensiones, o más si se utilizan N-gramas. El módulo de extracción de características de N-gramas le ofrece un conjunto de opciones para reducir la dimensionalidad. Puede elegir excluir las palabras que son cortas o largas, o demasiado poco comunes o demasiado frecuentes para tener un valor predictivo significativo. En nuestro experimento, excluimos los N-gramas que aparecen en menos de 5 registros.
Además, utilizamos la selección de características para obtener sólo aquellos valores que estén más correlacionados con nuestra predicción objetivo. Utilizamos la selección de características Chi-Cuadrado para elegir 50000 características. Podemos ver el vocabulario de palabras o N-gramas seleccionados haciendo clic en la salida derecha del módulo Extraer N-gramas.
Utilizamos el módulo Red neuronal multiclase para crear un modelo de red neuronal que pueda utilizarse para predecir un objetivo que tenga múltiples valores. Además, utilizamos el módulo Tune Model Hyperparameters para construir y probar modelos utilizando diferentes combinaciones de ajustes, con el fin de determinar los hiperparámetros óptimos para la tarea de predicción y los datos dados.
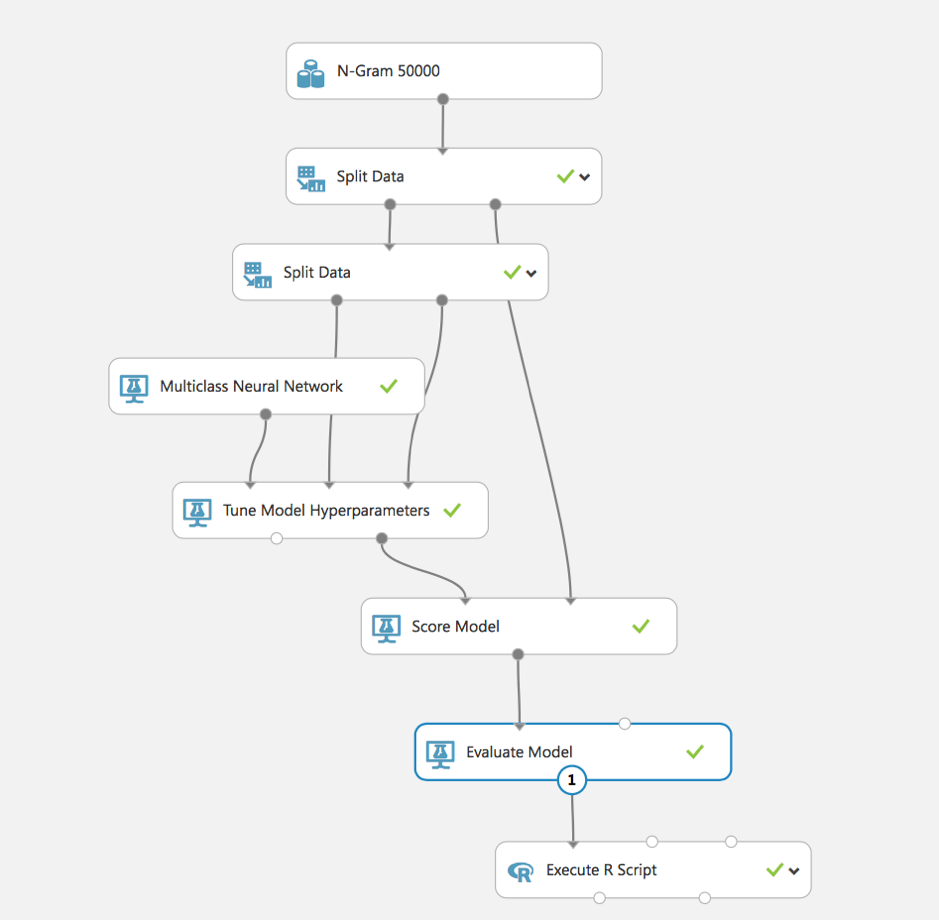
Al principio, dividimos los datos para el entrenamiento y el conjunto de datos de puntuación, lo que significa que seleccionamos una parte de los datos que no se incluirá en el proceso de entrenamiento pero que se utilizará como datos de prueba para el cálculo de la precisión.
En el segundo paso, también dividimos el conjunto de datos de entrenamiento para afinar los hiperparámetros del modelo. Después, configuramos el modelo principal de nuestro experimento: la red neuronal multiclase.
Tras el entrenamiento, podemos puntuar y evaluar el modelo para analizar la precisión recibida.
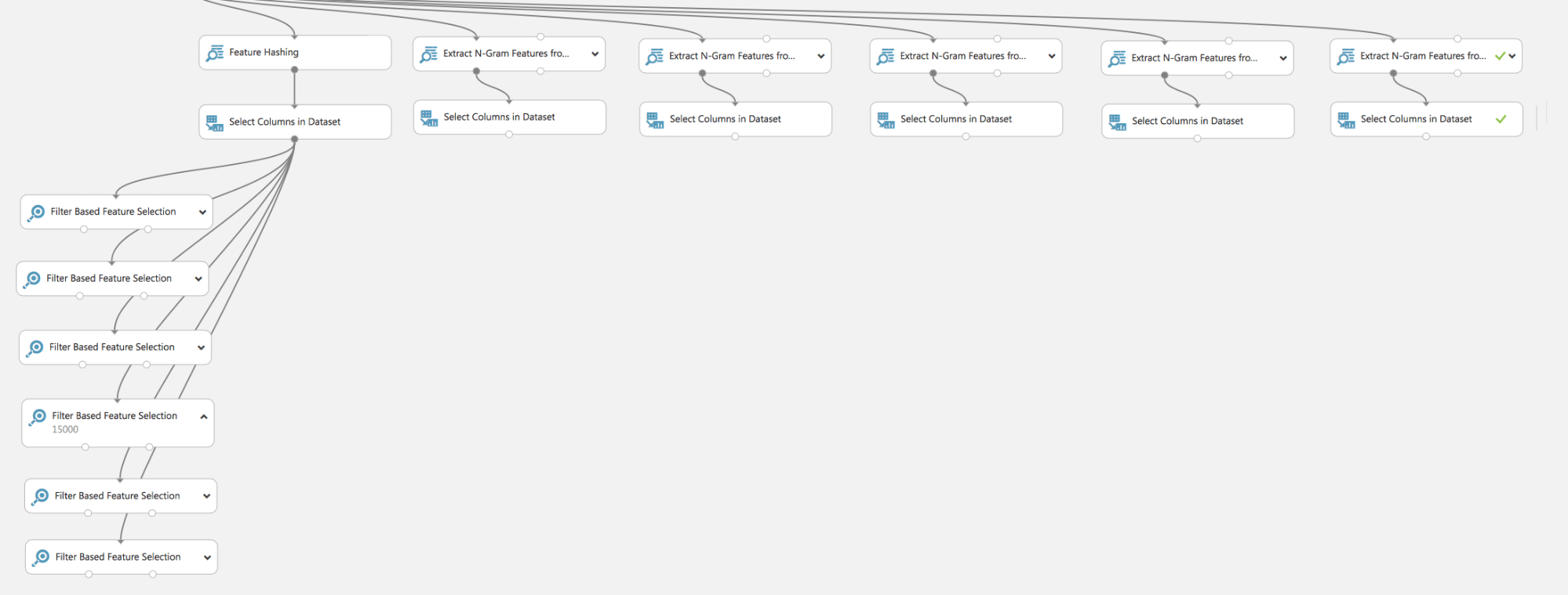
Como vemos, en unos pocos pasos bastante sencillos, hemos construido un modelo para resolver un problema práctico. Por supuesto, se han omitido algunos pasos, por ejemplo, la búsqueda del método óptimo de procesamiento de texto TF / TF-IDF y sus parámetros:
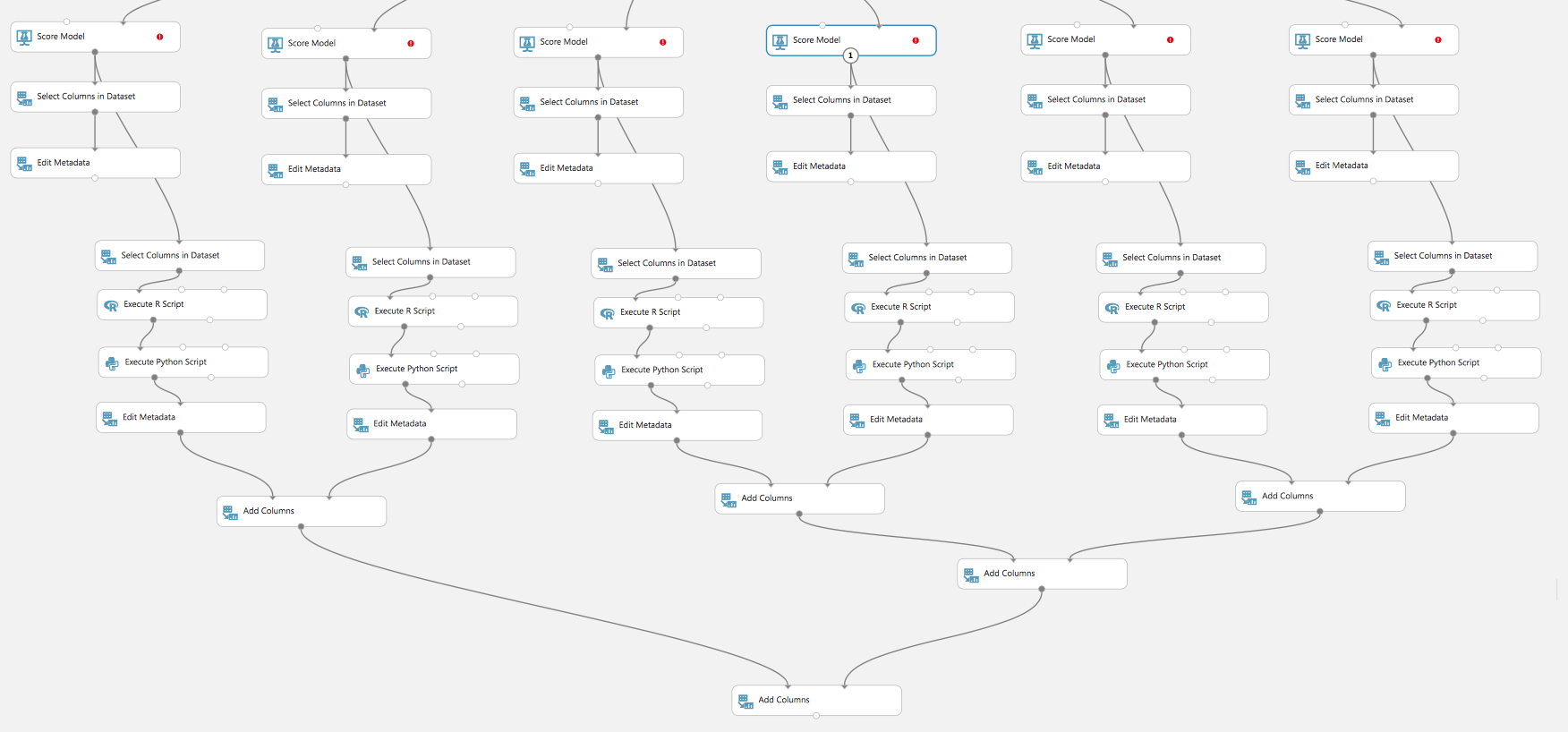
O la comparación de la calidad de diferentes modelos:
En este artículo, intentamos mostrar un ejemplo de uso de ML y Azure ML Studio para resolver un problema práctico. Por supuesto, lo mostramos brevemente – ya que el desarrollo de modelos para el Procesamiento del Lenguaje Natural es un tema para todo el libro, y el artículo puede convertirse en un libro de texto para ML, NLP, Azure ML Studio.
Pero lo principal es que demostramos que es posible construir tales modelos de forma sencilla y rápida, teniendo los conocimientos iniciales de ML, la herramienta demostrada – Azure ML Studio lo permite.
Por supuesto, no cubrimos todos los aspectos de ML y de ML Studio, no consideramos otros tipos de modelos, no mostramos cómo seleccionar eficazmente los parámetros de los modelos – desde simples regresiones lógicas hasta redes neuronales. No mostramos cómo construir redes neuronales con diferentes tipos de funciones de activación y redes multicapa. Todo esto se podrá exponer en el próximo artículo.
Acerca de Redwerk
Redwerk es una empresa de desarrollo de productos de software en régimen de externalización que es experta en ofrecer soluciones informáticas de última generación para empresas de todos los tamaños. Nuestros sectores de interés son el comercio electrónico, la automatización de empresas, la sanidad electrónica, los medios de comunicación y el entretenimiento, la administración electrónica, el desarrollo de juegos, las startups y la innovación. Uno de los puntos fuertes que hemos adquirido dentro de la dilatada experiencia profesional es proporcionar a las empresas beneficios tecnológicos de computación en la nube. Optimizamos los procesos de flujo de trabajo y utilizamos el mejor conjunto de herramientas para estos fines: el servicio de desarrollo de aplicaciones azure. Para dar rienda suelta al poder de las capacidades digitales de última generación, contrate a un equipo dedicado que hemos reunido a fondo en años para convertirse en un solucionador de problemas cotidianos y estratégicos de las empresas.


