
Cuando oímos hablar de “Ruby”, a menudo lo asociamos con “Ruby on Rails”. Rails es un framework muy funcional y popular que se utiliza ampliamente para la construcción de APIs y aplicaciones web. Rails consta de gemas independientes y ActiveRecord es una de ellas. Esta potente gema simplifica las operaciones con las bases de datos, permite trabajar con ellas de forma orientada a objetos y también hace que Ruby on Rails sea finalmente popular entre los desarrolladores.
Pero existen numerosos cuellos de botella a la hora de trabajar con ActiveRecord. Muchos desarrolladores suelen olvidar, ignorar o simplemente desconocer estos problemas. Al principio del desarrollo del proyecto no afecta al rendimiento de la aplicación, pero más adelante puede convertirse en un dolor de cabeza.
En nuestra experiencia, hemos tratado con muchos proyectos grandes que incluían bases de datos, con numerosas tablas, relaciones simples y complejas. En uno de esos proyectos, nos enfrentamos al problema: las peticiones a un servidor llamaban a demasiadas consultas a una base de datos. Y junto a las operaciones útiles, había un montón de consultas innecesarias que ralentizaban considerablemente el rendimiento
Cuando miramos por primera vez el registro de la consola, nuestra reacción fue un poco abrumadora y arreglar todos esos problemas debía llevar mucho tiempo y esfuerzo. Así que aceptamos el reto de limpiar el sistema de esas consultas, reescribir algunas de ellas para optimizar el tiempo de ejecución, reorganizar el código y hacer “todo lo posible para acelerar el sistema”
A continuación encontrará los errores típicos y las soluciones que nos ayudaron a cumplir nuestros objetivos.
Para mostrarle la diferencia en la velocidad de ejecución de las consultas, todos los ejemplos descritos en este artículo utilizan una estructura de BD sencilla que creamos para las pruebas. Contiene cuatro modelos: Usuario, Hotel, Empresa, País con columnas típicas. Sembramos la BD con datos de prueba y añadimos 100k usuarios, 100 hoteles y 1k empresas
También utilizamos el módulo Benchmark de Ruby para probar el tiempo de ejecución de nuestros ejemplos de código
Comencemos.
Consulta N+1
El error más fácil y uno de los más típicos, que en realidad ralentiza el rendimiento general del sistema. Aunque es bastante obvio, hemos decidido mencionar este problema, porque las formas de resolverlo también pueden afectar al resultado.
Como ejemplo, tomamos un modelo de Usuario y un modelo de País. El modelo de Usuario tiene la relación “belongs_to: :country”
El resultado debería ser la lista de usuarios con sus países.
users = User.limit(10)
users.each do |user|
puts “#{user.full_name} - > #{user.country.name}”
end
Cuando se empieza a trabajar con RoR al principio se piensa en este código como “¡¡¡Wow!!! Parece tan sencillo y ordenado. Y funciona!”
Pero echemos un vistazo más de cerca. En cada iteración del bucle, RoR llama a una consulta SQL para encontrar un país relacionado con un usuario de la iteración actual. Por lo tanto, llama a 1 consulta para cargar los usuarios, y a 10 consultas para cargar los países en cada bucle
Podemos optimizar fácilmente este problema procesando la lista con dos consultas:
Users.includes(:country).each do |user|
puts “#{user.full_name} - > #{user.country.name}”
end
En este punto los números pueden parecer muy pequeños, pero esta diferencia será tan grande como mayores sean sus cantidades de datos y la carga en los servidores.
Aunque, este error parece típico y fácil, es crucial evitarlo. Puede encontrar la descripción detallada de este problema en la documentación oficial de Ruby on Rails.
Uso de JOINS para evitar la consulta n+1
ActiveRecord tiene un método JOINS. Cuando lo utilizamos, ActiveRecord unirá la tabla pasada en la consulta (o, dependiendo de la sintaxis que utilice, añadirá la cadena JOINS pasada a la consulta). Normalmente, JOINS se utiliza para añadir cláusulas a las consultas
Así:
staff = User.joins(:hotel).where("hotels.name like '%Rixos%'")
Comprobemos cómo son los resultados de la consulta:
staff.each do |user|
puts “#{user.full_name} - > #{user.hotel.name}”
end
Observe los registros: JOINS no carga las relaciones y sólo se utiliza para filtrar los datos de una tabla relacionada. Utilizando este código volveremos al problema n+1 descrito anteriormente.
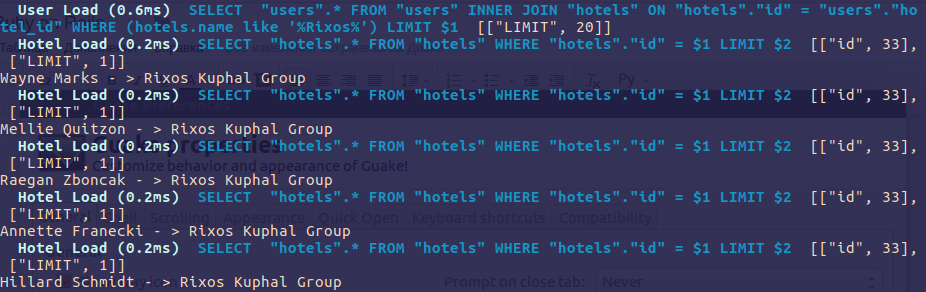
Usando INCLUDES en lugar de usar SELECT+JOINS
Cuando cargue algunos registros y relaciones, a menudo sólo necesitará uno o un par de campos de una tabla o tablas relacionadas.
users = User.includes(:hotel).limit(20)
users.each do |user|
puts "#{user.full_name} - > #{user.hotel.name}"
end
post_em]El benchmark devuelve 0,038902 segundos.[/post_em]
El problema está en que Rails asigna memoria para cada campo cargado. En algunos casos la tabla relacionada contiene muchas columnas y almacena muchos datos. Así que para qué cargar esos datos innecesarios si sólo necesita un campo (como en el ejemplo). Puede reescribir el código de la siguiente manera:
users = User.select('users.*, hotels.name as hotel_name').joins(:hotel).limit(20)
users.each do |user|
puts "#{user.full_name} - > #{user.hotel_name}"
end
COUNT/SIZE/LENGTH en objetos cargados
Una de las tareas básicas es mostrar un recuento de algunos registros. Hay tres métodos diferentes para hacer esto: RECUENTO, TAMAÑO Y LONGITUD
Y todos estos métodos funcionan de forma diferente:
- LENGTH carga todos los registros de la BD (si aún no se han cargado) y calcula su tamaño
- COUNT ejecuta una consulta SQL para calcular el recuento de registros en la BD
- SIZE comprueba si los registros se han cargado – pide el método LENGTH para el ámbito, en caso contrario ejecuta una consulta SELECT COUNT(*).
Así que si está absolutamente seguro de que no necesita una lista de registros de alcance entonces es mejor que utilice COUNT. Si no sabe si los datos serán cargados o no, entonces utilice el método SIZE. Esto le ahorrará consultas excesivas.
Además nos gustaría compartir con usted un pequeño truco. Imagínese que tiene un ámbito, y sabe que necesita cargar datos de ese ámbito y calcular su recuento. Pero primero queremos obtener el recuento de registros.
users = User.where(hotel_id: 1)
users_count = users.size
users.each do |user|
puts “#{user.full_name}”
end
Aquí están los registros de ejecución:
SELECT COUNT(count_column) FROM (SELECT 1 AS count_column FROM "users"
WHERE "users"."hotel_id" = 1) subquery_for_count
SELECT "users".* FROM "users" WHERE "users"."hotel_id" = 1
Pero en realidad puede hacerlo con una sola consulta, más optimizada. Lo único que tiene que hacer es añadir un método LOAD al ámbito. Los registros del ámbito se cargarán inmediatamente y el método SIZE no ejecutará una consulta SQL adicional.
users = User.where(hotel_id: 1).load
users_count = users.size
users.each do |user|
puts “#{user.full_name}”
end
Utilizando este código sólo habría una consulta en los registros:
SELECT "users".* FROM "users" WHERE "users"."hotel_id" = 1
Este truco es relevante en situaciones en las que cargamos datos de ámbito en cualquier caso, y no añadimos ámbitos adicionales a continuación.
Uso de cálculos en el lado de Ruby
Otra tarea popular es la de mostrar alguna información compleja sobre un usuario, que no puede ser cargada desde la BD en la condición en la que está almacenada.
Por ejemplo, tomemos dos modelos – Usuario y Empresa con asociaciones de muchos a muchos. Además el modelo Usuario pertenece al modelo Hotel. Queremos obtener un recuento de usuarios únicos por hoteles por cada empresa.
Puede calcularlo en Ruby de la siguiente manera
companies = Company.includes(:users).limit(100)
companies.each do |company|
puts company.users.map(&:hotel_id).uniq.count
end
Y podemos hacer los mismos cálculos, pero procesando el recuento en el lado SQL:
companies = Company.limit(100)
.select('companies.*, companies_hotels.hotels_count as hotels_count')
.joins('
INNER JOIN (
SELECT companies_users.company_id,
COUNT(DISTINCT users.hotel_id) as hotels_count
FROM users
INNER JOIN "companies_users" ON "users"."id" = "companies_users"."user_id"
GROUP BY companies_users.company_id
) as companies_hotels ON companies_hotels.company_id = companies."id"
')
companies.each do |company|
puts company[:hotels_count]
end
El aumento del rendimiento se debe a que todos los cálculos se realizan en la parte SQL y no se cargan datos innecesarios de la base de datos.
Abuso de las devoluciones de llamada de los registros activos
Las devoluciones de llamada en los modelos ActiveRecord son una herramienta muy potente que ayuda a gestionar el comportamiento de las entidades. Pero el uso excesivo de las devoluciones de llamada puede ralentizar considerablemente el sistema
Cuando añadimos una devolución de llamada a un modelo, se activa para cada evento (relacionado con esa devolución de llamada), pero algunas de las llamadas pueden ser redundantes. No realizan ninguna acción útil y pueden, por ejemplo, ejecutar consultas SQL inútiles, hacer algunos cálculos innecesarios, etc. Así que cuando añada una llamada de retorno a un modelo debe pensar primero si esta llamada de retorno es realmente necesaria para cada ejecución de un evento.
Para evitar esta situación puede mover el código de las devoluciones de llamada a métodos o clases y ejecutarlas sólo cuando sea realmente necesario. Esto realmente limpia y acelera su sistema.
Resumen
Como ve, hay muchos enfoques para implementar cualquier tarea básica con Ruby on Rails, pero no todos son útiles. Elegir una solución correcta acelerará definitivamente su aplicación y le ahorrará la dolorosa optimización posterior.
Para aquellos que prefieren confiar en servicios innovadores, existe una gran herramienta que ayuda a evitar algunos de los errores descritos anteriormente. Se llama Bullet y puede encontrarla aquí: https://github.com/flyerhzm/bullet
Acerca de Redwerk
Si está buscando desarrolladores externos cualificados, Redwerk es el lugar adecuado al que acudir. Ofrecemos servicios de desarrollo de software de externalización de alta calidad basados en nuestra amplia experiencia de trabajo con diferentes lenguajes y tecnologías de programación. Tanto si necesita servicios de creación de bases de datos como de desarrollo de Ruby on Rails, nuestro equipo estará encantado de participar y formar parte de su proyecto. También estamos reconocidos como una de las mejores empresas de Ruby on Rails en DesignRush.


