Gigmit




gigmit es un portal en línea de reservas de música en directo que ayuda a los artistas a reservar más conciertos y a los promotores a encontrar a los artistas adecuados. Utiliza algoritmos basados en datos para emparejar perfectamente a los artistas con conciertos, festivales y otros eventos, en función de su género, ubicación preferida y base de fans.
Todos los clientesExtracción de datos
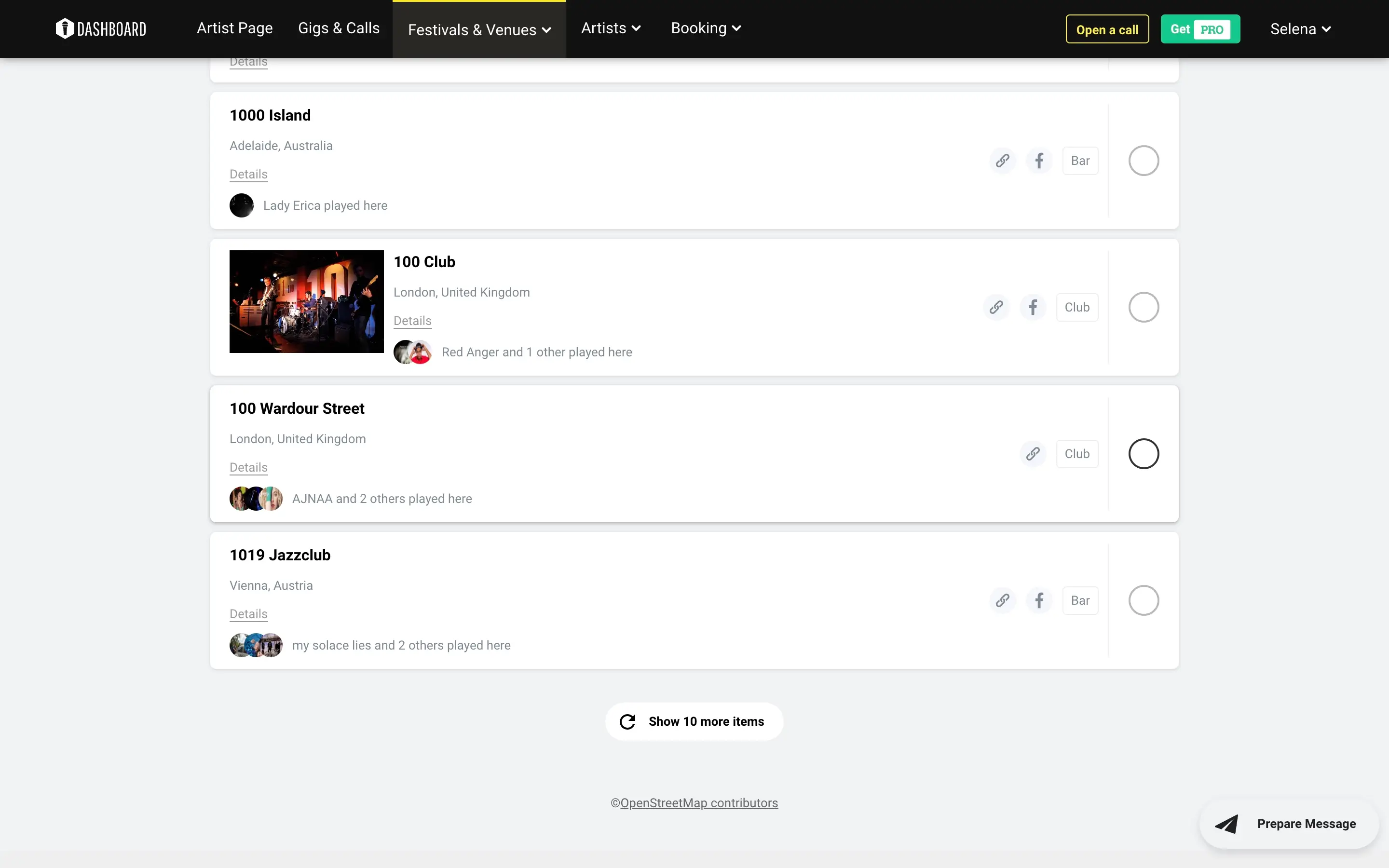
Ayudamos a gigmit a ampliar su base de datos con nuevos festivales, recintos e información de contacto y ubicación asociada. Utilizamos una combinación de solicitudes API y análisis sintáctico de HTML para recuperar y organizar los datos, respetando estrictamente sus requisitos de estructura de datos.
Más informaciónMedios de comunicación y entretenimiento
Ayudamos a gigmit a llevar a cabo su misión de hacer accesible a todo el mundo el negocio de la música en directo. Al ayudarles a aumentar y enriquecer su base de datos, proporcionamos a sus usuarios una oferta más amplia de oportunidades, lo que también se traduce en una mayor confianza y fidelidad de los consumidores.
Más informaciónDesafío
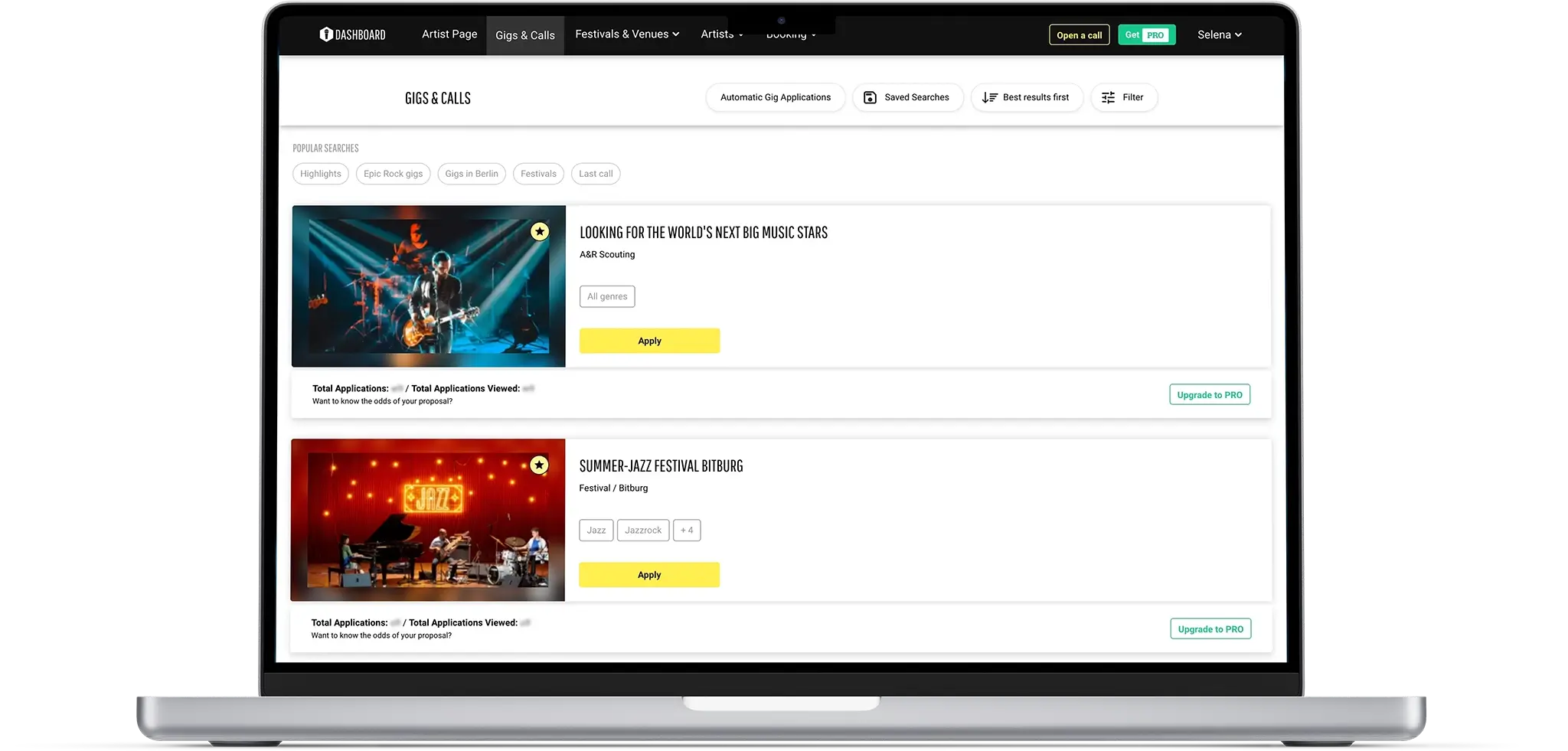
La naturaleza del negocio de nuestro cliente requiere una recopilación continua de datos para garantizar que los usuarios finales tengan cada vez más opciones relevantes y actualizadas. En pocas palabras, gigmit garantiza que los artistas puedan encontrar fácilmente los festivales de música, ferias, espectáculos o lugares para eventos especiales que deseen y ponerse en contacto con los organizadores.
Para lograr este objetivo, gigmit recopila en una única base de datos la información pública disponible en una plétora de sitios web de música y entretenimiento. Antes de nuestra colaboración, gigmit recopilaba los datos necesarios con la ayuda de Scrapy, un rastreador web de código abierto para extraer datos con API y raspado web de uso general.
Sin embargo, se enfrentaban a ciertas limitaciones con esta herramienta, por lo que recurrieron a Redwerk para que les ayudara a realizar el raspado de datos y el análisis sintáctico de un número selecto de recursos web. Naturalmente, debíamos hacerlo de forma que no perjudicara el funcionamiento de los recursos mencionados y sin bloquearnos. Además, teníamos que trabajar con limitaciones de tiempo.
Solución
El primer paso fue evaluar la estrategia de web scraping existente y seleccionar una nueva pila tecnológica que planteara menos restricciones de extracción y visualización de datos.
Elegimos Django REST para construir modelos de datos y gestionar las interacciones con la base de datos. Este marco nos permitió organizar y gestionar eficazmente los datos recopilados.
Creamos colas de tareas asíncronas con Celery y RabbitMQ para evitar sobrecargar los servidores con llamadas a la API. De este modo, nos aseguramos de que nuestras solicitudes se procesaran de forma ordenada y controlada.
La información de contacto sólo estaba disponible a veces, así que aprovechamos la potencia de Hunter.io, un buscador de correo electrónico basado en IA.
El mayor reto fue encontrar el equilibrio entre la velocidad de análisis y los límites de los servidores de alojamiento. Aun así, recopilamos éticamente todos los datos necesarios sin interrupciones del servicio ni quejas de los administradores de la web.
Resultado
Con nuestra ayuda, gigmit aumentó y enriqueció su base de datos de festivales de música, lugares para eventos especiales, pubs, cines, centros de arte, teatros, junto con los conciertos asociados y los datos de contacto. Entregamos datos bien estructurados en tablas SQL y archivos XLSX en línea con los requisitos de la estructura de datos. El éxito de gigmit como empresa se basa en datos actualizados y relevantes, y nosotros les ayudamos a disponer de ellos a tiempo para que sus suscriptores pudieran ver todas esas oportunidades y solicitar los conciertos adecuados.
Estamos orgullosos de que gigmit se expanda a Estados Unidos, y seguiremos apoyándoles y compartiendo nuestra experiencia tecnológica para garantizar su crecimiento constante en los próximos años.
En prensa
De todas las plataformas, gigmit es la que está causando más sensación. Fundada en 2012, la web es una especie de Tinder para la industria musical, que pone en contacto locales y artistas perfectamente emparejados.
Aprovechamos los datos y defendemos que sean accesibles de forma transparente. En algún momento seremos capaces de predecir la afluencia a un concierto en el futuro.
"gigmit" se lanzó bajo el lema "Simple booking. Reservar simplemente", el 11 de noviembre de 2012. En su décimo aniversario, gigmit cuenta con 225.000 usuarios de más de 120 países.

Una solución digital podría simplificar el mundo de la música en directo y ayudar a ambas partes: dar a los promotores una visión más filtrada y ayudar a los artistas a ver dónde están las oportunidades.

¿Necesita una herramienta fiable para recopilar datos de forma segura?
Hable con expertosTecnologías
 Django REST
Django REST Celery
Celery Hunter.io
Hunter.io PostgreSQL
PostgreSQLComentario del equipo Redwerk

Oleksandr
Desarrollador
Utilicé una combinación de solicitudes API y análisis de páginas HTML para recopilar los datos necesarios. Apliqué estrategias probadas para evitar saturar los servicios de los que se recogían los datos. Este proyecto requirió un poco de resolución de problemas, pero una vez seleccionada la pila tecnológica adecuada, todo resultó muy claro y sencillo.
Relacionado en Blog

Cómo elegir la pila tecnológica adecuada para su proyecto
El desarrollo de software es un asunto complicado. Cada proyecto es principalmente el concepto y las personas que dan vida a este concepto. Los plazos, los recursos y, por supuesto, las tecnologías, suelen definirse a posteriori. Pero eso no implica que la elección de las tecnolo...
Leer más
Cómo rastrear un sitio web protegido: Una mirada en profundidad
Los rastreadores web son programas de descarga y procesamiento masivo de contenidos de Internet. También se les suele llamar "arañas", "robots" o incluso simplemente "bots" En esencia, un rastreador hace lo mismo que cualquier navegador web ordinario: envía peticiones HTTP a los ...
Leer más¿Impresionado?
Contrate nuestros serviciosOtros casos prácticos
Orderstep
Ayudamos a aumentar los ingresos por suscripciones desarrollando un módulo de tienda web premium

CDP Blitz
Optimización de la base de datos y mejora de la funcionalidad del directorio de medios con más de 35.000 contactos
My Bike Valet
Presencia en línea y solución móvil para un sistema inteligente de aparcamiento de bicicletas